
awpak78 发表于 2024-2-29 17:15
NAS赶上SSD,100GbE网络大升级,升完只差100G
看起来目前版本没有比samba快多少, 而且你那还是傲疼, 只 ...
awpak78 发表于 2024-2-29 17:15
NAS赶上SSD,100GbE网络大升级,升完只差100G
看起来目前版本没有比samba快多少, 而且你那还是傲疼, 只 ...
iooo 发表于 2024-2-29 16:59
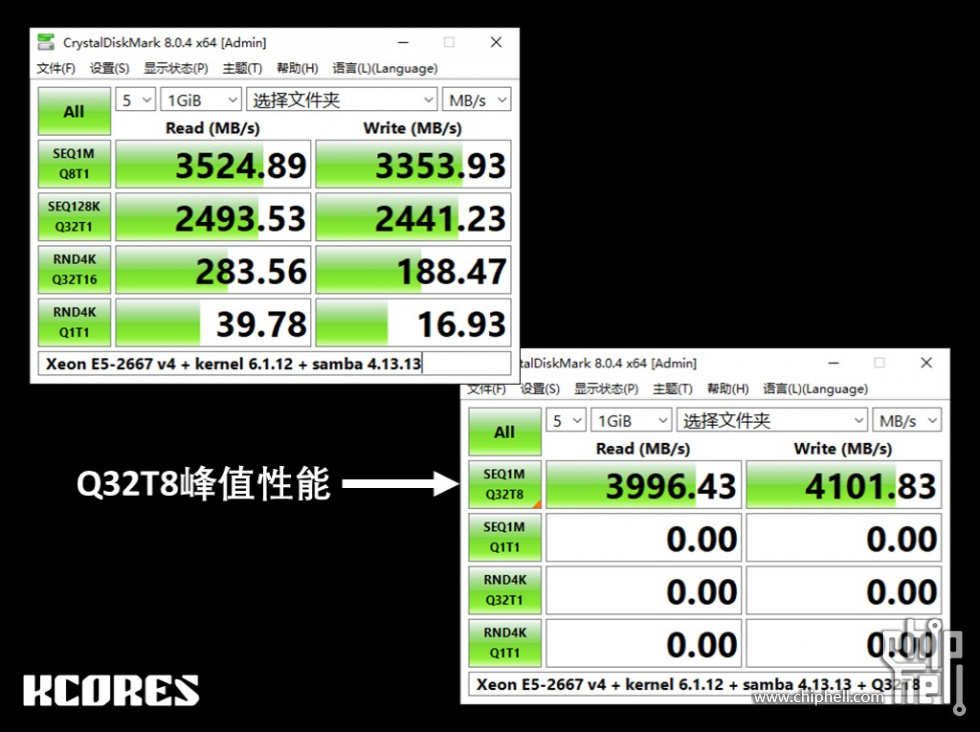
感觉非常牛,有详细点的步骤吗,炒个作业
summerq 发表于 2024-3-1 02:23
你说的这个我也配置成功了,接下来尝到甜头之后,你就会琢磨如何提高4k性能以便加快小文件读写速度。然后你 ...
QSG 发表于 2024-3-1 09:36
rdma的优势在这种低速环境下根本不在速度啊,要不你看看我的nas,猜猜这个是什么系统 ...
赫敏 发表于 2024-3-1 10:11
光看数据我还以为七彩虹固态。结果905p
RDMA是条死路,上限太低了尤其是4k。等哪天有DPU大船了再来组NAS
赫敏 发表于 2024-3-1 10:11
光看数据我还以为七彩虹固态。结果905p
RDMA是条死路,上限太低了尤其是4k。等哪天有DPU大船了再来组NAS
Dolfin 发表于 2024-2-29 21:46
按你的理解,RDMA是死路,所以DPU就跟RDMA没关系了?
Exfat 发表于 2024-2-29 21:36
dpu大船早就有了 博通的ps225 而且bf2的价格已经算是很便宜了
Dolfin 发表于 2024-3-1 10:09
我这是Windows NAS,不用猜了。
Dolfin 发表于 2024-3-1 09:45
KSMBD是个内核空间的服务,SPDK是个用户空间的工具包。
SPDK的优势就是在内核空间IO,它的传输方案SPDK n ...
Dolfin 发表于 2024-3-1 09:45
KSMBD是个内核空间的服务,SPDK是个用户空间的工具包。
SPDK的优势就是在内核空间IO,它的传输方案SPDK n ...
赫敏 发表于 2024-3-1 10:11
光看数据我还以为七彩虹固态。结果905p
RDMA是条死路,上限太低了尤其是4k。等哪天有DPU大船了再来组NAS
summerq 发表于 2024-2-29 22:38
dpu都是提供块设备共享,没有基于文件的。你可千万别买那个辣鸡博通的dpu,因为块设备共享你用nvmeof就完 ...
summerq 发表于 2024-3-1 11:05
实际上我是分成两步的。首先是spdk通过vhost target来提供块存储空间到qemu,然后虚拟机的内核空间通过vi ...
Dolfin 发表于 2024-3-1 15:43
这个方案约等于SPDK用Vhost给VM提供了块存储,而QEMU还是运行在用户空间,SPDK也在用户空间。我并没有虚 ...
Dolfin 发表于 2024-3-1 10:09
我这是Windows NAS,不用猜了。
aixunxian 发表于 2024-3-2 14:55
为啥你这个cdm跑出来顺序写入这么低呢?顺读都11G/s了写咋才5G/s
aixunxian 发表于 2024-3-2 14:55
为啥你这个cdm跑出来顺序写入这么低呢?顺读都11G/s了写咋才5G/s
summerq 发表于 2024-3-3 03:08
有几个方向可以试试。
1. 排除掉硬盘带来的影响。用tmpfs创建一个64g的挂载点,然后用ksmbd来试试。ramdisk ...
summerq 发表于 2024-3-3 03:11
另外补充一下,windows本身可能是瓶颈,不妨换linux用FIO看一下。如果你一定要用windows客户端就算了 ...
summerq 发表于 2024-3-3 03:11
另外补充一下,windows本身可能是瓶颈,不妨换linux用FIO看一下。如果你一定要用windows客户端就算了 ...
Dolfin 发表于 2024-3-3 13:36
ACM这个文得看一阵子了,感谢分享。
一些关于底层存储的额外说明:
1.实验只用了一块Optane,挂载XFS,测 ...
summerq 发表于 2024-3-3 16:37
首先谢谢您的分享,很有帮助!
我这边会找时间测试一下。我的硬件没有你好,optane已经放在软路由上了, ...
Bloodyevil 发表于 2024-3-3 18:06
小文件读写可以测试下iser应该可以提升不少,以前在Ubuntu环境下搭建过感觉跟本地盘无区别。 ...

Dolfin 发表于 2024-3-3 15:54
从我的理解来看,小文件随机读写使用的是模式是RDMA send/receive操作,是一种双边操作,而不像 RDMA re ...
summerq 发表于 2024-5-15 02:38
今天跑了一下 我只有25g网卡。linux端是connectx-4 lx,开rdma,ssd是大普微h3200。
window这边环境比较 ...
Dolfin 发表于 2024-5-15 09:19
感谢测试,这次测试涉及到SPDK吗?还是只涉及到KSMBD。
从截图看,性能表现很好。
summerq 发表于 2024-5-15 10:29
1. 没有spdk,只有ksmbd。我这边没有遇见4k暴跌的问题
2. 以前遇见过,现在没有了。这个可能跟内核自带的 ...
Dolfin 发表于 2024-5-15 11:15
我看你现在的测试,1016MB/s 的4k q32t16的数据是在TCP下的成绩(资源管理器还能侦测流量),RDMA下能到 ...
Dolfin 发表于 2024-5-15 11:15
我看你现在的测试,1016MB/s 的4k q32t16的数据是在TCP下的成绩(资源管理器还能侦测流量),RDMA下能到 ...
summerq 发表于 2024-5-15 13:20
刚才又测试了一下:
服务端直通一个1.4T optane 905p
Dolfin 发表于 2024-5-15 19:16
我q32t16从tcp的4000多直接拉到不到800。。我是没搞明白它的传输机制,而且为什么tcp能到那个数字,这超 ...
老饭 发表于 2024-5-15 19:59
why not nvme-of
summerq 发表于 2024-5-15 19:55
拉到如此之低 我怀疑跟rdma的驱动有关系。晚上我编译一个原厂驱动替换试试 ...
Dolfin 发表于 2024-5-15 20:39
我以前问过ksmbd的作者Namjae Jeon关于4k的状况,他推荐我看看这个,也分享给你。https://www.snia.org/s ...
Dolfin 发表于 2024-5-15 20:39
我以前问过ksmbd的作者Namjae Jeon关于4k的状况,他推荐我看看这个,也分享给你。https://www.snia.org/s ...
summerq 发表于 2024-5-16 22:23
我想我发现原因了。我是在pve内vm上跑ksmbd,nvme通过vfio直通。今天偶尔发现,vfuo的性能有问题。可能真 ...
summerq 发表于 2024-5-16 19:19
看过了。我粗略地理解就是 rdma做smb共享时数据包还是要经过内核tcp协议栈,而nvmeof + spdk不用,因此效 ...
| 欢迎光临 Chiphell - 分享与交流用户体验 (https://www.chiphell.com/) | Powered by Discuz! X3.5 |