
a010301208 发表于 2025-2-12 15:26
要382GB内存的
后天 发表于 2025-2-12 15:29
内存对于显卡来说 不算贵了 而且没有卡脖子
bigeblis 发表于 2025-2-12 15:34
4090岂不是还要涨????
我輩樹である 发表于 2025-2-12 15:30
它的性能提升是基于selectively using 6 experts的。deepseek r1有256个专家模型,按top8来选择激活。 ...
我輩樹である 发表于 2025-2-12 15:26
说下它们的配置:
CPU: Intel (R) Xeon (R) Gold 6454S 1T DRAM (2 NUMA nodes)
bigeblis 发表于 2025-2-12 15:37
666666
魔幻
我用了两年的卡,现在卖了不但不会亏钱,还能赚一笔。
StevenG 发表于 2025-2-12 15:36
简单点来说,就是处理一次请求时,只加载部分模型?
a010301208 发表于 2025-2-12 15:26
要382GB内存的
MikuLuka 发表于 2025-2-12 15:40
手里二手ESC4000A-E10 DDR4*8都能512,,如果是真的那条件要求阵地
看U的需求了7002/7003好多定制版U贼便 ...
dexterchen 发表于 2025-2-12 15:24
哈哈
32G的9070XT市场来了
KimmyGLM 发表于 2025-2-12 15:41
D4 没前途的,早点切换为D5
equaliser 发表于 2025-2-12 15:40
大陆存量4090越来越值钱了
wjm47196 发表于 2025-2-12 15:48
要cuda环境和牙膏amx指令集加速,看看后面有没有大佬弄rocm和epyc版的
我輩樹である 发表于 2025-2-12 15:30
它的性能提升是基于selectively using 6 experts的。deepseek r1有256个专家模型,按top8来选择激活。 ...
StevenG 发表于 2025-2-12 15:52
看原始新闻的截图,就是3090+epyc7402+200g内存
wjm47196 发表于 2025-2-12 15:52
不用这个选项就好了,255个token/s还不够用?
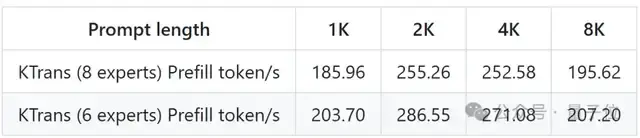
我輩樹である 发表于 2025-2-12 15:59
top8其实差不多。prefill阶段的。
wjm47196 发表于 2025-2-12 16:01
问题是最后效果如何?选这么少的专家单元感觉会有影响啊
wjm47196 发表于 2025-2-12 16:01
问题是最后效果如何?选这么少的专家单元感觉会有影响啊
我輩樹である 发表于 2025-2-12 15:39
专家模型都存在cpu里面,每次推理的时候,按照router专家给出的建议,将需要参与激活的专家模型从cpu交换 ...
zhuifeng88 发表于 2025-2-12 16:11
不交换到GPU的,就CPU推理,交换到GPU激活expert也有20B参数量,别说pcie了,nvlink4都不如CPU直接推快, ...
KimmyGLM 发表于 2025-2-12 16:13
作为菜鸡问下,那为何不能直接效仿矿机,搞ASIC+大显存+NPU来做?
赫敏 发表于 2025-2-12 16:14
牢英生不逢时。还有救吗?
KimmyGLM 发表于 2025-2-12 16:13
作为菜鸡问下,那为何不能直接效仿矿机,搞ASIC+大显存+NPU来做?
我輩樹である 发表于 2025-2-12 16:17
能别提npu么。。。npu是做无感推理用的。不是搞这种重负荷的东西。
wjm47196 发表于 2025-2-12 15:54
github开源页面有写啊,树大已经丢了
255.26 (optimized AMX-based MoE kernel, V0.3 only)
...
StevenG 发表于 2025-2-12 16:22
这是最新版本支持了amx加速,我说的不是官方的总结,你看贴的新闻链接,原始的新闻里,有网友用3090和740 ...
我輩樹である 发表于 2025-2-12 15:26
说下它们的配置:
CPU: Intel (R) Xeon (R) Gold 6454S 1T DRAM (2 NUMA nodes)
zcyandrew 发表于 2025-2-12 16:25
它大概的idea是模型放cpu里,用4090来加速一些适合gpu架构的运算?

zcyandrew 发表于 2025-2-12 16:25
它大概的idea是模型放cpu里,用4090来加速一些适合gpu架构的运算?
ITNewTyper 发表于 2025-2-12 16:27
按照这个趋势 到时候16GB也能跑了。
显卡危机来了
后天 发表于 2025-2-12 15:29
内存对于显卡来说 不算贵了 而且没有卡脖子
fcs15963 发表于 2025-2-12 16:35
6000的内存,12000的显卡
 只要14g+cuda,那目前最便宜的新卡那不就是4060ti 16g
只要14g+cuda,那目前最便宜的新卡那不就是4060ti 16g
KimmyGLM 发表于 2025-2-12 16:13
作为菜鸡问下,那为何不能直接效仿矿机,搞ASIC+大显存+NPU来做?
ltpterry 发表于 2025-2-12 17:38
Cerebras,Groq,还有某些Google TPU出来自己做的(他们是不是给自己取了一个LPU的新名字)。
具体到部 ...
ITNewTyper 发表于 2025-2-12 16:27
按照这个趋势 到时候16GB也能跑了。
显卡危机来了
uprit 发表于 2025-2-12 17:47
实际跑起来就需要14G显存,16G完全够用
KimmyGLM 发表于 2025-2-12 16:06
8 expert正好就对应一张显卡,等于KTransfomer 把其他层的expert都砍了;
zhuifeng88 发表于 2025-2-12 17:52
没跑过才说的出这话...16g几百context就不行了,几百context给谁用啊,拉起来就跑个hello llm图一乐吗 ...
zhuifeng88 发表于 2025-2-12 04:55
没砍啊....MoE就是这样工作的 原始的是每层256 expert 每个token都动态选中top8 对于每一个token,在每层 ...
赫敏 发表于 2025-2-13 02:01
每一个token都选不同模型,那输出token不是乱了?

| 欢迎光临 Chiphell - 分享与交流用户体验 (https://www.chiphell.com/) | Powered by Discuz! X3.5 |