

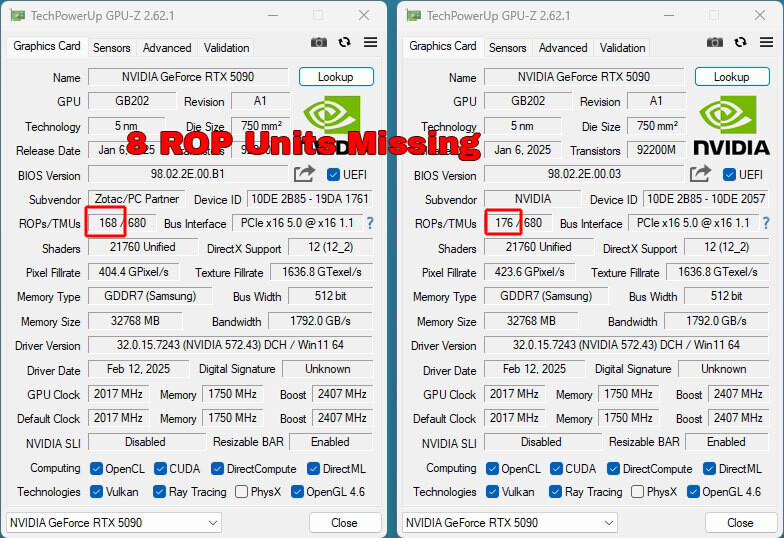
 5070ti也少rops,而5080这个完整核心的没事,挺幽默的。
5070ti也少rops,而5080这个完整核心的没事,挺幽默的。airforce18 发表于 2025-2-22 12:10
官方有说怎么处理吗?
airforce18 发表于 2025-2-22 12:10
官方有说怎么处理吗?
airforce18 发表于 2025-2-22 12:10
官方有说怎么处理吗?
punk100 发表于 2025-2-22 12:10
这是切除的不干净,切偏了一点?
Scarlet〃 发表于 2025-2-22 12:05
5070ti也少rops,而5080这个完整核心的没事,挺幽默的。
allensakura 发表于 2025-2-22 12:48
我最近一直在看UE5相关的的玩意
基本可以得出一个结论,那就是不论是EPIC还是NV都认为4K渲染未来一点都不重 ...
allensakura 发表于 2025-2-22 12:48
我最近一直在看UE5相关的的玩意
基本可以得出一个结论,那就是不论是EPIC还是NV都认为4K渲染未来一点都不重 ...
黄伟达:净事房捅的篓子 关我什么事 我户部只管韭菜收成。。。顺带一提因为5090和4090恰好都是启用11组GPC,所以反映到实际产品上他俩也恰好都是176个ROPs
PPXG 发表于 2025-2-22 13:19
甚至GB202依然保持12组GPC不变的情况下塞下了24576CUDA,为此需要每组GPC的TPC数量从6增加到8,但是ROP单元 ...
理智的边缘 发表于 2025-2-22 13:07
这也能带上 UE5我是没想到的。建议去看看虚幻5文档,1080P 60FPS的渲染目标指的是在主机上,人家当然是根 ...
ONEChoy 发表于 2025-2-22 13:10
黄伟达:净事房捅的篓子 关我什么事 我户部只管韭菜收成。。。
PPXG 发表于 2025-2-22 13:19
甚至GB202依然保持12组GPC不变的情况下塞下了24576CUDA,为此需要每组GPC的TPC数量从6增加到8,但是ROP单元 ...
punk100 发表于 2025-2-22 12:10
这是切除的不干净,切偏了一点?
faimie6183 发表于 2025-2-22 13:54
从15年春泰坦x到16年夏泰坦p到17年春泰坦xp再到18年底泰坦rtx,
长期保持96rop雷打不动 ...
LOLI反应堆 发表于 2025-2-22 12:33
50系只是没有达到我们心目中的预期而已,不代表它效率下滑。
5090,5080,5070Ti,都是性能提升≥粗大提升, ...
heroyours 发表于 2025-2-22 14:12
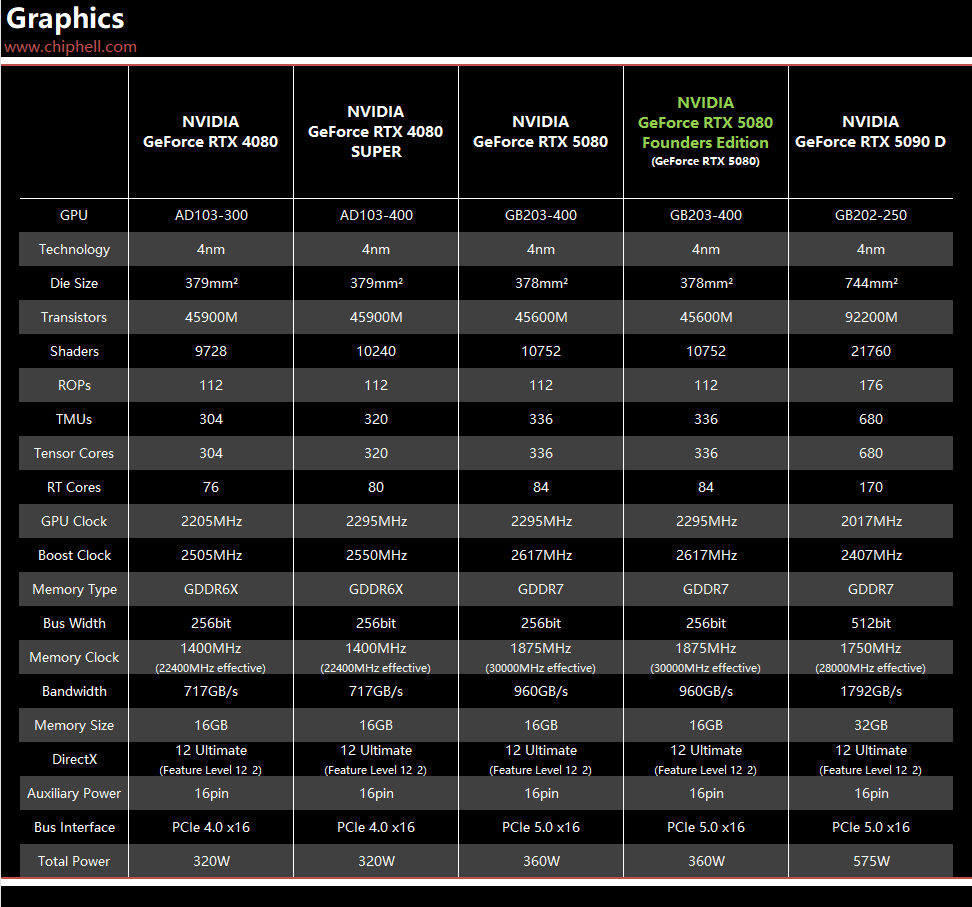
50系效率没有下滑,但也基本没有什么提升。5080比4080s 4k平均12%的性能增幅,cuda多了5%,rop单元多了14 ...
LOLI反应堆 发表于 2025-2-22 14:36
GB203和AD103 rops一样的啊,它们都是7GPC。
考虑到5080频率还低一点,像素填充率应该也低一点。 ...
heroyours 发表于 2025-2-22 14:55
rop我看错了,不好意思。5080频率不低啊,同为fe,5080fe的boost频率还更高。
LOLI反应堆 发表于 2025-2-22 14:58
在游戏里普片要低一点。40系都是2800mhz+,5080和5070Ti大部分时间都是2750mhz甚至不到。 ...
heroyours 发表于 2025-2-22 14:12
50系效率没有下滑,但也基本没有什么提升。5080比4080s 4k平均12%的性能增幅,cuda多了5%,rop单元多了14 ...
heroyours 发表于 2025-2-22 14:12
50系效率没有下滑,但也基本没有什么提升。5080比4080s 4k平均12%的性能增幅,cuda多了5%,rop单元多了14 ...
chungexcy 发表于 2025-2-22 15:05
你咋不对比4080的规模呢
PPXG 发表于 2025-2-22 13:19
甚至GB202依然保持12组GPC不变的情况下塞下了24576CUDA,为此需要每组GPC的TPC数量从6增加到8,但是ROP单元 ...

punk100 发表于 2025-2-22 12:10
这是切除的不干净,切偏了一点?
ghgfhghj 发表于 2025-2-22 15:27
没法再加gpc了,12gpc已经相当低效了,从结果看4090到5090性能是跟着核心规模走的,可以说是比较理想了已 ...
aasa0001 发表于 2025-2-22 20:08
扯淡。
光栅化在gpc上,gpc数量就是最核心的瓶颈,再加上是通用瓶颈的互联和L2。 ...
fzyw 发表于 2025-2-22 15:09
不是12%是16%,而且算上dlss4的提升,5080的优势会更大。
heroyours 发表于 2025-2-22 22:50
4k平均12%的性能增幅是参考chh5080fe的评测。算肯定是传统性能,加了dlss就没意思了。用个软件就把对手压 ...
heroyours 发表于 2025-2-22 22:50
4k平均12%的性能增幅是参考chh5080fe的评测。算肯定是传统性能,加了dlss就没意思了。用个软件就把对手压 ...
fzyw 发表于 2025-2-23 07:42
继续加强dlss技术就是今后nvidia的发展方向,5090和5080开启dlss4后获得的帧数,如果光靠堆硬件你觉得什 ...
aibo 发表于 2025-2-23 14:58
黄卡rops的配置从maxwell开始就没变
前端是gpc输出瓶颈,后端rop(早期和显存控制器绑定,著名的970 3.5G) ...
ghgfhghj 发表于 2025-2-22 20:42
堆gpc有边际效应,n卡5gpc-7gpc效率最高,11gpc的4090边际效应比起7gpc的4080就相当明显
5090继续维持11 ...
aibo 发表于 2025-2-23 14:58
黄卡rops的配置从maxwell开始就没变
前端是gpc输出瓶颈,后端rop(早期和显存控制器绑定,著名的970 3.5G) ...
aasa0001 发表于 2025-2-23 19:04
废话,增大规模,效率永远是降低的。
扩大面积、增加互联节点->互联延迟上升
cache/compute相对下降->cac ...
| 欢迎光临 Chiphell - 分享与交流用户体验 (https://www.chiphell.com/) | Powered by Discuz! X3.5 |