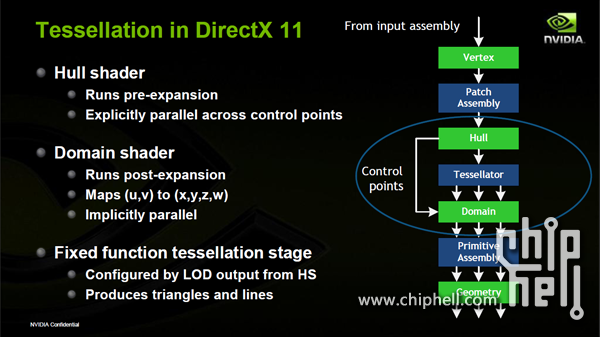
| 作为新一代的Fermi架构,我们不得不感叹相对于GT200的巨大变化,可是在细致观察之后我们又会产生这样的疑问:Fermi架构的重点服务对象到底是单纯的PC GAME还是GPGPU计算?首先是针对DX11重要变革的Tessellation(中文名为曲面细分)的优化:
Fermi在加入多形体引擎之后的三个流程分别在一些不同的元器件中间处理,其中曲面细分器Tessellator是完整的在多形体引擎中间实现的.这三个环节怎么工作呢?Hull shader有部分的工作是用CUDA核心工作的,这个部分所起到的任务是决定现在这个曲面要如何被细分,它首先去计算这个曲面根据当前的LOD,所谓的景深,就是细节的级别程度决定要把它分成一千格还是分成一万格.在被Hull Shader决定了以后,就转到Tessellator上,Tessellator是一个硬件固定的功能元器件,它会被固定放在多形体引擎中执行.Tessellator的功能是把刚刚被Hull shader决定要细分多少个曲面的参数确定下来,同时把这些曲面细分出来.Hull shader决定怎么切,Tessellator把按照刚才LOD的定义分割下来,分割完成之后,最后交给Domain Shader,Domain Shader有部分的工作也是回到CUDA运算核心区做,CUDA核心最后把这些细分的曲面,哪些需要贴图置换的,把需要置换的帖图帖上去,所以是一个完整的流程.Hull shader决定如何切割,Tessellator算好结果切割开,然后Domain Shader把需要的贴图置帖上去,这就是Fermi处理DirectX 11(以下简称DX 11)中间曲面细分的完整过程. 再谈曲面细分.我们在HD5800系列评测的时候已经完整地解读过了DX 11的几个更新内容,其中曲面细分是DX 11的一个重要升级,更精美的贴图效果,以及智能化的表现形式,将会使DX 11的画面与效率得到以往所无法达到的新高峰.虽然这样说会显得很笼统,一般玩家可能无法理解,我用一个简单的例子来让大家更好的理解:以往我们看到GAME中的头发往往是非常简单,或者说索性带着帽子以及头盔来避开头发的渲染,这是因为要做到逼真的头发必须让GPU同时渲染大量的三角形,无形中降低了引擎的效率增加了GPU的负荷,而有了曲面细分之后,并不是说头发变得更加容易渲染了,而是通过画面的远近不同,头发上的"面"(也就是三角形的数量)会自动发生变化,就如人的视觉一样,1米内你看对方的头发很会清晰,可是10米内呢?100米你呢?你已经不可能再看到一根根发丝,曲面细分做到的就是视野的远近不同3D图形上的面也不同,近距离的时候为了使画面逼真,一个面将会被细分成成千上万个面,而当你离开物体越来越远,成千上万个面又会自动缩小成几十个面,甚至到最后只有一个面,这样一来GPU运算的负载便会被智能化的调整,而有了曲面细分技术之后3D设计师们也就可以不再为华丽的3D画面而担心GPU负载不了了.
Fermi图形架构采用的整体架构分成三个部分: 第一个部分称之为GPC(GPU Processor Cluster图形处理器集群),GPU中间拥有四个GPC,在首先大的架构上分成四个GPU,每一个GPU中间又拥有4个SM模块,4个SM模块每个SM模块里面又对应32个CUDA处理核心.在民用桌面级的GF100,GTX480架构上拥有15组SM,470拥有14组SM,也就是说,GTX 480已经被屏蔽了1组 SM(每组SM具有32个CUDA,或者说是SP),而GTX 470则被屏蔽了2组 SM.此外,每一组SM的模块都是进行一个乱序指令的执行,而且在4组GPC中间加入大容量的L2,这个二级缓存可以被4组GPC,15组的SM和超过480个CUDA cores一起调用,不得不承认Fermi是个GPU史上非常革命性的架构.
第二,加入一个光栅引擎,光栅引擎可以做到比如像以前我们在做传统的贴图或者传统的材质纹理贴图方式的架构的处理中间所不能做的功能.我们在每一个GPC中间加入一个光栅引擎,整个GTX480系列总共拥有4个光栅引擎.单从GPU运算能力上来对比,这一代的Fermi架构上比上一代GT200拥有8倍的性能提升.
在Tessellation的实际测试和应用的时候,这个部分是把整个GTX480 15组SM处理的模块单独提出一组来,我们看到这些绿色的都是CUDA核心,每组SM都有32个CUDA核心.这一代比上一代的SM有非常大的改变,首先每一个SM里面有32个CUDA核心,4倍于上一代GT200的架构.上一代GT200每一组SM里面,只有8个CUDA核心. 第三,在缓存方面,刚才讲了L2缓存,而L1缓存也同样非常具有有革命性.在每一个SM里面,都内嵌了64K的缓存.这64K的缓存被划分成两个部分,一个部分是所谓的shared memory,一个部分是L1的缓存.根据微软D 11的定义,在每一个时钟周期内,可以采用一种配置模式,在下一个时钟周期,可以让程序员控制转变为另外一种控制模式.我们的一级缓存拥有两种模式,第一种是把48K划分给shared memory,16K划分给L2;第二种模式是倒过来,16K给shared memory,48K给L1.这样的好处是,这个程序员在编程的时候,对于第一级返程将更加灵活. 我们可以简单设想一下,今天这个纹理非常非常小,打个比方,这个纹理只要16K,这个情况下,我们可以允许程序员把L1定义成只有16K,剩下的48K全部交给shared memory,而shared memory在这样的情况下,可以更快跟本地的显存之间做数据的预读取工作,而L1里面已经存在了当前这个纹理.由于一整片的渲染,比如我在渲染一片草地,这片草地的纹理是固定的,这个时候,L1的命中率是非常高的,每一个CUDA核心,每一个所谓在运算的环节中间,一旦要去存L1的时候,可以立即运用L1里面的内容,所以L1有16K就够了,48K可以做其他的事情.当情况反过来,场景快速变化的时候,L1要做的更大,比如从草地过渡到海洋的时候,有一部分的L1是草地的纹理,有部分的L1是海洋的纹理,这个时候对L1的容量要求就更大了,因为如果只有16K的L1,它的命中率会非常低,因为它要频繁在海洋和草地中做切换.这个时候,我们允许程序员把L1变成shared memory.这是一个非常灵活的弹性设计,这也是在我们这一代中对整个memory最大的变革. |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-10-26 21:39 , Processed in 0.006528 second(s), 7 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.