|
发布时间: 2023-6-2 13:40
正文摘要:本帖最后由 fpd92axv 于 2023-6-2 13:45 编辑 农吧看到的,顶针? |
本帖最后由 raiya 于 2023-6-3 23:54 编辑 HaYuanJi 发表于 2023-6-3 08:26 1,下载安装,这部分自己去看。基本逻辑就是架设一个本地的服务器,然后用浏览器去访问自己这个本地服务器使用。git clone之类的,你就当在dos之类的界面下,去执行一个下载安装命令。 2,基本结构,模型基分为checkpoint , LORA, hypernet,embiding。 checkpoint是大模型,一个2G~。这个东西是包含着生成图片的时候的绝大部分内容和基础,在生成图片的时候只能选一个,相当于选一个模式。当然咯,这个东西也是可以训练的,是可以几个模型合并的。 然后下面那些都是小模型,是可以用词条添加在图片生成内容里面的,没有数量限制。 embiding,基本上就是权重改变,容量很小,无法为大模型引入新内容。 hypernet,这个东西比上面那个大,是可以引入新内容的。但是这个东西的问题在于它的优先级甚至高于大模型checkpoint,相当于直接给画师的脑子动刀了,很难用。 lora,主要用的是这个。和hypernet一样,是可以引入新内容的。它的特点是优先级低于checkpoint,所以它可以引入新内容,但是不影响checkpoint的基本内容。 以上模型,embiding和hypernet可以在SD主页训练。checkpoint和lora需要另外的安装kohya服务器训练。 3,使用方面的基础知识。 首先生成图片,是选择一个checkpoint,然后增加正负词条,和LORA。 初步生成的一般只有512X512左右尺寸的图片,最大不超过1024x1024。然后再去用算法放大到高清。 因为呢,首先AI的原理,就算是512x512的图片,但是生成或者训练的时候,是以维度为单位的,所以占用的资源是指数级。4090也就能生成原生1200左右的图片了。 然后因为上面的原因,大部分的模型就是依照512x512的像素去训练的。而AI画图,实际上它只是模仿。你给他训练的时候是512的,你让他一次性画1024图,他只会画成 4个512的,结果就是画出来4个脑袋之类的。 而高清放大,实际上也是把画面分割成小块,让AI画小块然后拼起来。 而为什么要用正负词条呢。因为训练的时候,要素不会那么干净。训练的时候,一张图片,会标注这张图片上是什么,但是AI实际上是不懂的。所以你比如说,你训练的时候,你把几张【小美】的照片,拿来标注。里面有几张是在家里背景有个电视,有几张在路上背景有辆车,比把电视和车都标注了出来。但是当你在添加词条的时候,只添加了lora:小美,那么很有可能那个电视机,那辆车,也会被一起画出来。怎么办,这时候就必须在负面词条里面,加上车和电视机,那么很大概率就不会跑出来。 之前说过的hypernet和lora的区别。举个例子,你用的checkpoint大模型,是一个汉服动画风格的。而如果你用一样的小美的照片,各训练一个hypernet和一个lora,都叫做小美。你在词条里面添加hypernet 小美,那么生成的图片很有可能就很像你训练的时候的照片,背景有一点点汉服动画风格。如果你添加的是一个lora小美,那么你会得到一个汉服动画人物,脸长得有点像小美。这就是他们的区别。 4,其他的插件,训练,都是日新月异的,时不时可以去看看。但是AI画图基本上不是一次性生成一张成功的高清图片这样玩的,更有可能是随机生成图片,或者用现成的图片,然后在图片生成图片那里,然后修改一部分,有点像PS的用法。 |
Victor.dou 发表于 2023-6-3 13:20 牛逼。。 |
大头吃小头 发表于 2023-6-3 13:24 这么速度 |
Victor.dou 发表于 2023-6-3 13:21 那挺快的 |
| A卡硬件还行,就是驱动太拉了。 |
卡卡鸡 发表于 2023-6-3 08:17 10秒吧 6900xt 512*512几秒出 768*512 |
卡卡鸡 发表于 2023-6-3 08:17 RX6700XT 按照 Tom's Hardware文章的测试参数,跑512x512, 100it 约16秒,6.25it/s. |
imluvian 发表于 2023-6-3 02:36 官方不做RDNA游戏卡的 rocm 测试和验证,所以不加进支持列表。 可以加环境变量来支持RDNA 1+2 游戏卡。
|
散了吧,就支持7900,6000系列及以下不知道以后会不会支持,我的580 2048sp画色图速度看了下只有4-5s/lt(win系统) ,出个图要1分多-2分钟,有没有6000系列的说说出个图要多长时间 ,出个图要1分多-2分钟,有没有6000系列的说说出个图要多长时间 |
Victor.dou 发表于 2023-6-2 16:37 ROCM不是不支持RDNA的游戏卡吗。。 |
|
现在单说AI性能 能跟2060 12G相当的A卡是什么型号? |
atiufo 发表于 2023-6-2 23:53 可能是,之前没深入研究,等7900XTX到了再试一下 |
lyf362345 发表于 2023-6-2 14:37 你多虑了,这个提升仅限于7000系  至于出图畸形多是因为你的反面tag添加得不够 |
灵乌路空 发表于 2023-6-2 22:39 双倍FP别想用上了 |
| 我超 阿尔卑斯 |
|
修复了那双倍FP单元没用上的问题? 还是单纯的Direct ML效率的问题? |
| 6000系列显卡SD跑图效率有提升吗 |
|
几个月之前拿RX6700XT测试过,Windows directml 速度只有 Linux rocm 的一半。 一直传言 rocm 5.6 会支持Windows,再等几个月看看 pytorch rocm版 有没有更新。。 |
| 为啥要用coreml 扔wsl里不好吗 |
| 卧槽,刚买7900xtx就来这种好事??? |
xudi8092 发表于 2023-6-2 15:39 Windows下不可以。 Linux下我不**楚。 |
itisfine 发表于 2023-6-2 15:32 大佬,这个可以训练模型吗 |
xudi8092 发表于 2023-6-2 14:18 你要下载AMD专用的。 我7900xt用下面这个能正常使用: https://www.bilibili.com/video/B ... f768f1509078bc8ec0b |
|
玩这个别给自己整hard难度,搭环境debug以及遇到问题搜不到解决方法非常恼人 sdwebui这种可以无脑搭建的都能劝退不少人,以至于他们宁愿去用在线的 |
|
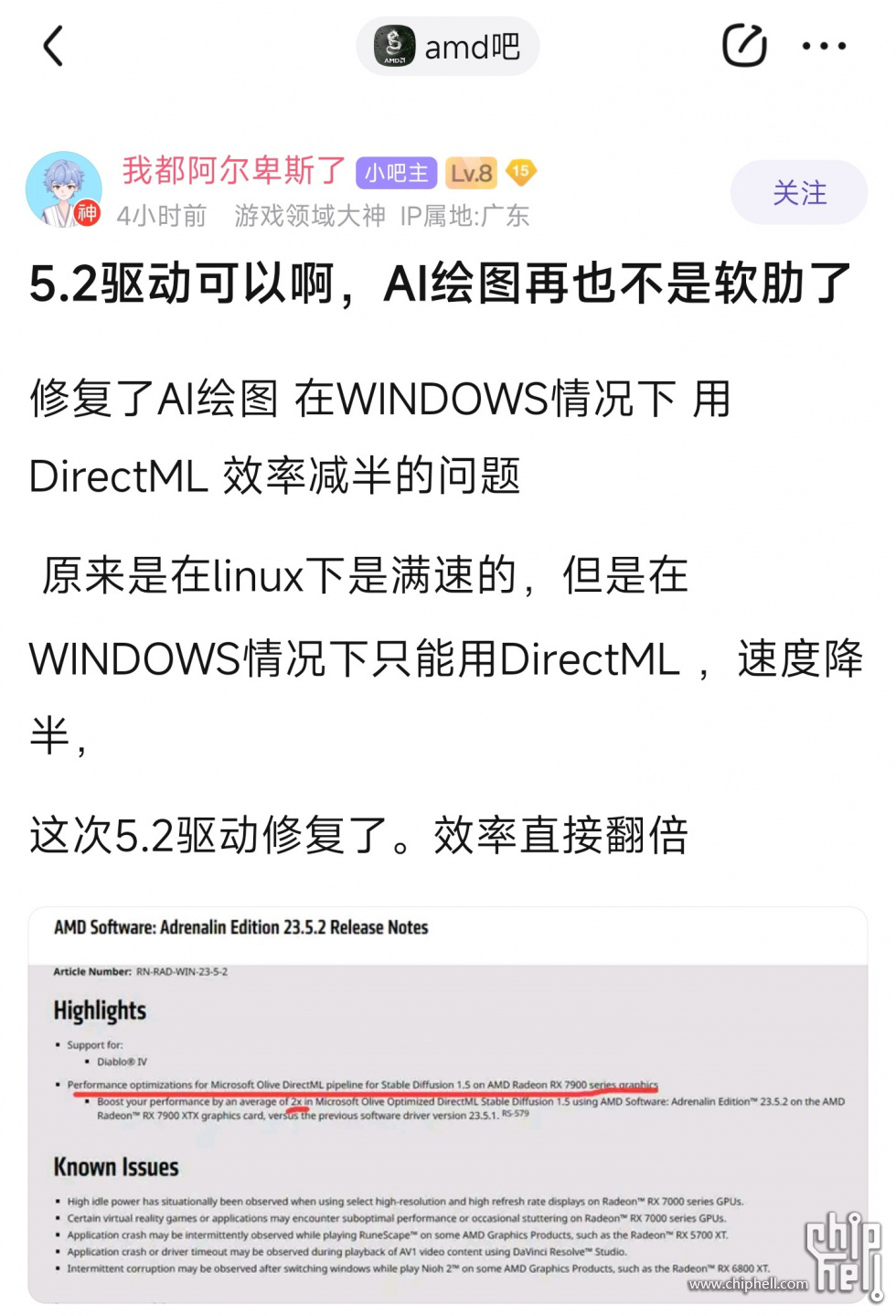
本帖最后由 Misaka_9993 于 2023-6-2 15:00 编辑 只优化了RDNA3架构,也就是RX7000系列。跟老卡没啥关系了。 https://gpuopen.com/amd-microsoft-directml-stable-diffusion/ https://devblogs.microsoft.com/directx/dml-stable-diffusion/ These optimizations have been validated on AMD RDNA™ 3 devices that feature compute units with AI accelerators, including AMD Radeon™ RX 7900 Series graphics cards. |
| 5700XT,我之前只能画384以下的图,而且画出来都是畸形儿,不知道是不是也是这bug导致的。 |
23.5.1是个很稳定的版本,没用两天就5.2了 |
itisfine 发表于 2023-6-2 14:06 我下载的sd整合包,根本就识别不了a卡。 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-6-23 18:34 , Processed in 0.013436 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.