|
发布时间: 2023-7-10 16:43
正文摘要:本帖最后由 godspeed66 于 2023-7-18 14:42 编辑 一、fp16性能 和bf16性能 GPU Compute Capability 来源于 https:// ... |
我輩樹である 发表于 2023-7-19 07:20 感谢 又多了一个可以商用的模型啦 不知道这个模型(预训练数据)的中文质量如何? |
zhuifeng88 发表于 2023-7-19 00:01 num_machines=1 num_processes=$((num_machines * 1)) machine_rank=0 accelerate launch \ --config_file ./configs/sft.yaml \ --num_processes $num_processes \ --num_machines $num_machines \ --machine_rank $machine_rank \ --deepspeed_multinode_launcher standard finetune_moss.py \ --model_name_or_path ./fnlp/moss-moon-003-base \ --data_dir ./sft_data \ --output_dir ./ckpts/moss-moon-003-sft-t01 \ --log_dir ./train_logs/moss-moon-003-sft-t01 \ --n_epochs 2 \ --train_bsz_per_gpu 1 \ --eval_bsz_per_gpu 1 \ --learning_rate 0.000015 \ --eval_step 1000 \ --save_step 1000 gradient_accumulation_steps: 1 假设改成 8,学习率是不是也要相应成倍增加? |
|
https://huggingface.co/meta-llama llama2出了,楼主可以试试。 |
|
本帖最后由 zhuifeng88 于 2023-7-19 00:04 编辑 bs调大同时等比例调大gradient_accumulation_steps....有offload的情况下设1大部分是气泡难怪了, micro batch size不要动, 你这个数值不在accelerate的config里, 应该是训练脚本在控制 |
zhuifeng88 发表于 2023-7-18 17:42 求指点  compute_environment: LOCAL_MACHINE deepspeed_config: gradient_accumulation_steps: 1 gradient_clipping: 1.0 offload_optimizer_device: cpu offload_param_device: cpu zero3_init_flag: true zero3_save_16bit_model: true zero_stage: 3 distributed_type: DEEPSPEED downcast_bf16: 'no' dynamo_backend: 'NO' ipex_config: ipex: true fsdp_config: {} machine_rank: 0 main_process_ip: null main_process_port: null main_training_function: main mixed_precision: bf16 num_machines: 1 num_processes: 56 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: true |
godspeed66 发表于 2023-7-18 15:17 方便的话你还是贴一下deepspeed配置, moss全参数微调bs和throughput的关系不至于这样 |
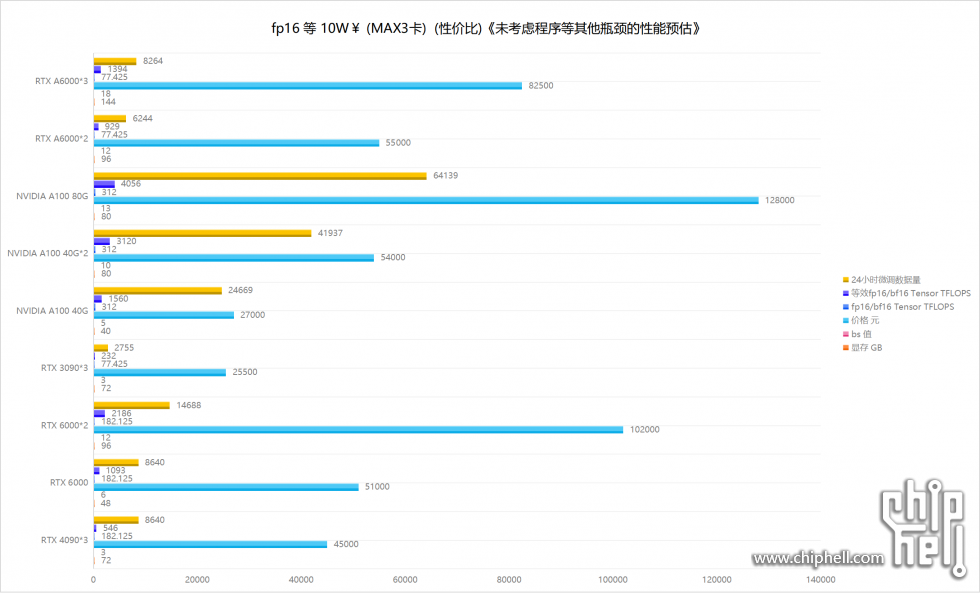
godspeed66 发表于 2023-7-18 14:59 可以见到,随着显存的增大,即bs值的增大,可以显著的减少训练时间 为什么4090 的数值是0,那是因为即使bs=1 也需要31GB显存才能跑起来。 目前性能瓶颈是CPU单线程性能,大部分时间是CPU单线程100%在跑,GPU平均使用率低于50%。 最后结论是,目前个人娱乐学习建议使用多张RTX3090、RTX4090; 如玩LLM建议起始选择RTX A6000 48GB,建议选择RTX 6000 ADA,毕竟RTX 6000 ADA的bf16/fp16性能是RTX A6000的2倍; 而且RTX 6000 ADA还支持FP8格式,未来fp8的llm程序更新后,RTX 6000 ADA 有着恐怖的728.5 TFLOPS fp8性能,对比RTX 6000的 77.425 TFLOPS fp16性能,RTX 6000 ADA近乎10倍的计算性能。 |
godspeed66 发表于 2023-7-12 13:31 初步怀疑是显存爆了,导致CPU一直100%,进而导致运算速度异常 从bs=2开始再次测试 |
cutezzk 发表于 2023-7-12 14:10 谢谢 但这个太抽象了,我玩大语言模型,需要的是准确的fp16或bf16性能,以及参考fp8性能 |
lz可以参考下这个tf16的表格,来源:https://www.tomshardware.com/news/stable-diffusion-gpu-benchmarks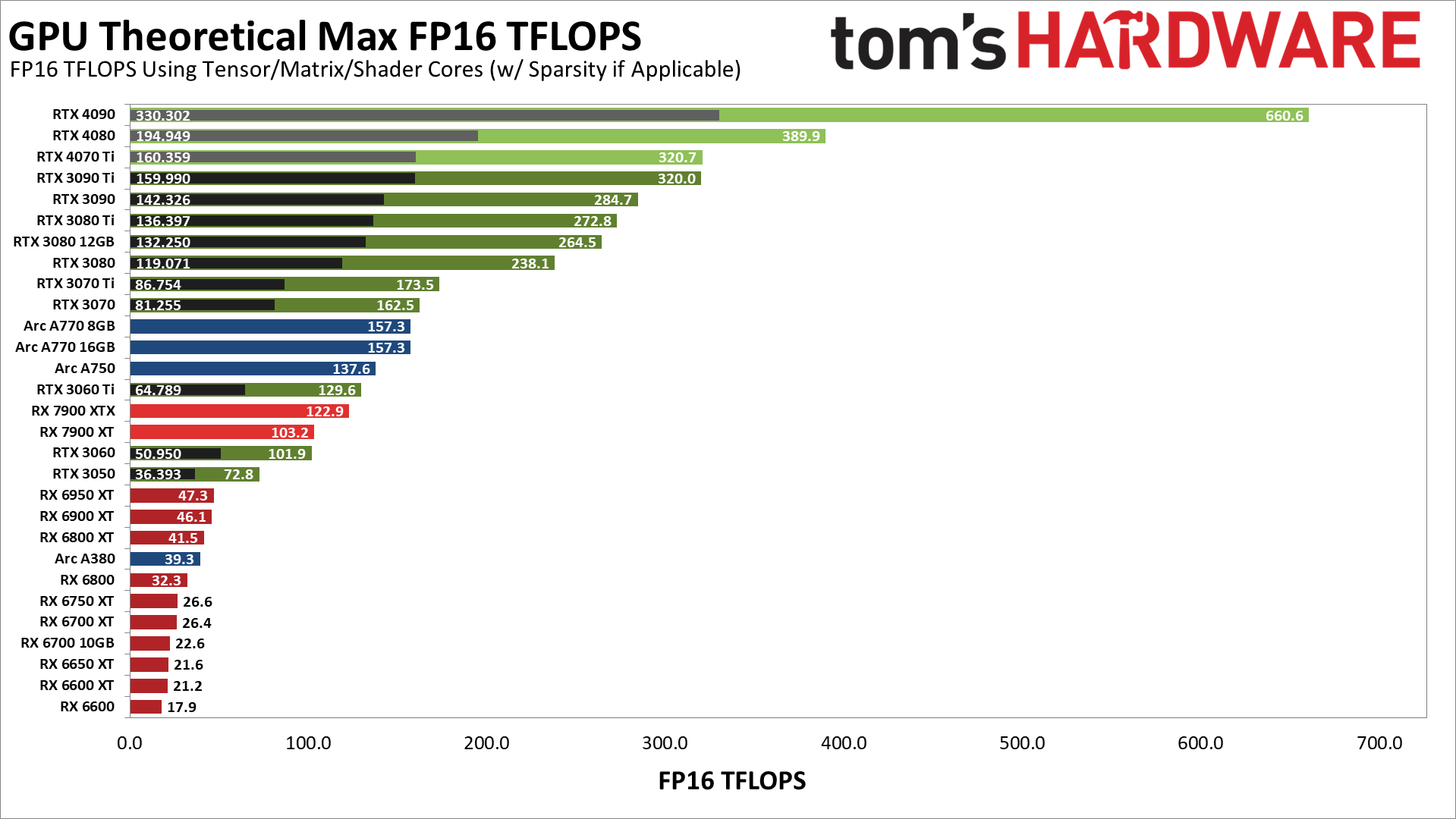 |
zhuifeng88 发表于 2023-7-11 18:05 我都郁闷啦 bs=1 运行一段时间后显存都能使用到31GB |
本帖最后由 godspeed66 于 2023-7-14 16:46 编辑 godspeed66 发表于 2023-7-11 14:31 fp8 翻车了 鉴于在容器中运行fp16的微调也异常的慢,我怀疑是WSL中使用容器的问题 我先慢慢研究下 =========================== 2023.7.14 确认是我的程序在容器里对FP8支持不好,疑似是deepspeed offload到cpu后有异常,导致运算特别慢 fp8测试暂停,待以后解决直接在系统环境部署Nvidia Transformer Engine成功后再测试 |
本帖最后由 zhuifeng88 于 2023-7-12 17:48 编辑 godspeed66 发表于 2023-7-11 14:08 稍微补点测试数据 我这没有6000ADA所以拿3090和A40对比, 测试代码用lambdalabs的falcon-7b微调例子, 用deepspeed, frozen参数4bit https://github.com/LambdaLabsML/examples
可以看到在合理设置下, A40在接近单卡3090 2.8倍的batchsize下, 完成一个epoch的时间只会比单卡3090少22% 而4卡3090(无nvlink)的速度是单卡A40的3.1倍 |
|
稍后晚上我完善 RTX 6000 ADA 用fp8的性能 折腾4小时没配置好环境,最后直接用的nvidia容器 |
本帖最后由 godspeed66 于 2023-7-11 14:29 编辑 我輩樹である 发表于 2023-7-11 14:23 非常感谢 RTX 6000 和RTX A6000我也没找到nvidia的官方材料 我是参考了H100的官方介绍 https://www.nvidia.cn/data-center/h100/ “ * 采用稀疏技术显示。在不采用稀疏技术的情况下,规格降低一半。 ” 根据H100 在不采用稀疏技术的情况下,规格降低一半的描述,计算的RTX A6000 和RTX 6000的fp16性能,以及RTX 6000的fp8性能 |
godspeed66 发表于 2023-7-11 14:17 根据squeezellm的最新研究成果,llm可以提高到稀疏度0.45%。稀疏性能仅用于可以压缩的部分。 |
godspeed66 发表于 2023-7-11 14:08 24小时微调数据量之前就说过你这个受batchsize影响很大的情况是训练设置不合理造成的, 正常情况下batchsize 2和batchsize 6, 每epoch时间差异应当是很小的, 不会出现3卡4090和单卡6000ada差不多的情况 |
godspeed66 发表于 2023-7-11 14:02 我不知道你上哪看的数据... fp16/bf16(fp32acc) 3090FE是71, A6000是77, 4090FE是165才对 |
我輩樹である 发表于 2023-7-10 19:07 非常感谢  |
本帖最后由 zhuifeng88 于 2023-7-10 19:22 编辑 godspeed66 发表于 2023-7-10 19:00 最近两代通常使用只需要关心fp16/bf16 tensor performance Compute Capability 8.6和8.9 都是 fp16 性能= fp32性能 但这不重要, 因为大部分使用的fp16性能是由tensorcore提供的, 标注为tensor performance, 性能全都是fp16(fp16acc) = 2 * fp16/bf16(fp32acc) = 4 * tf32, 加粗的是使用最普遍的 更进一步的, 8.9的fp8 = 2 * fp16(fp16acc) 取决于写法, 都可以在训练中用到, 不仅仅用于推理 |
| 另外文本类的transformer模型是相对density的模型,所以sparse性能肯定是达不到标称的值。 |
godspeed66 发表于 2023-7-10 19:00 这个取决于代码如何写的,但另外的帖子里面你说你用的deepspeed,现代一点的框架都能利用tensor core,你只需要关注tensor的性能就行了。 |
我輩樹である 发表于 2023-7-10 18:28 是的 已经单卡在跑了,预计要跑18万条数据,时间不能容忍,18天才能跑一个epoch 打算扩计算卡,预算有限 ,看到显卡数据蒙了,我不知道我微调以及推理用的是显卡数据表上的Tensor performance 性能 还是 Single-precision performance 换算出的fp16性能 例如 RTX 6000 ADA (RTX4090 ) ,Single-precision performance是91 TFLOPS,根据 https://docs.nvidia.com/cuda/cud ... hmetic-instructions,得出fp16 性能=fp32的性能=91TFLOPS; 官方介绍说,RTX 6000的第四代张量核心的性能是fp8 1457.0 TFLOPS(换算非稀疏 fp8 728.5TFLOPS),我不知道是不是可以理解成第四代张量核心的fp16性能和bf16性能都是728.5/2=364.25 ? RTX A6000 (RTX 3090) ,Single-precision performance 是38.7 TFLOPS,根据 https://docs.nvidia.com/cuda/cud ... hmetic-instructions,得出fp16 性能=fp32的性能*2=77.4TFLOPS; 官方介绍说,RTX A6000 的第三代张量核心的性能是 Tensor performance 309.7 TFLOPS(没明确说是fp8)换算非稀疏 fp8 154.85TFLOPS),我不知道是不是可以理解成第三代张量核心的fp16性能和bf16性能都是154.85/2=77.425 TFLOPS 我微调ChatGLM 或者MOSS 到底用的是Tensor performance 的fp16性能呢? 还是Single-precision performance对照“Arithmetic Instructions”得出的fp16性能呢? |
| 是微调吧,主要是看你基于的模型的量化程度。一般一个预训练大语言模型都会发布多个量化的版本,即使没有别人也会帮他量化。如果基于fp16的量化版本,就可以用fp16微调。很多llm甚至有4bit的模型。 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-11-4 06:33 , Processed in 0.012371 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.