|
发布时间: 2024-7-16 12:56
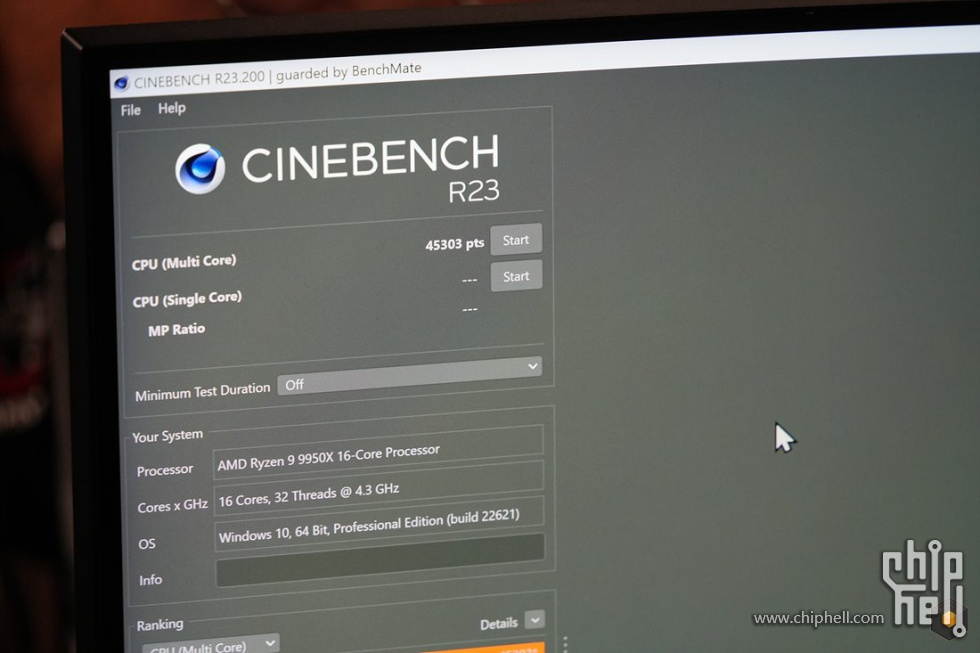
正文摘要:本帖最后由 gihu 于 2024-7-18 20:15 编辑 如图,外网已经有完整的R23 多核默认、PBO、超频和液氮的跑分(液氮跑的53XXX分) ,包括GB6单/多核,CineBench R15、Wprime等液氮超频成绩。 ... |
gihu 发表于 2024-7-20 19:17 cpu渲染和gpu渲染其实很难绝对比较效率,因为越是高级复杂的材质和光效,后者的效果就比前者差,gpu渲染是用更低的算法精度求误差大的近似值(无论渲染采样开多高都无法完全得到cpu的效果,因为gpu目前的光追算法是从cpu的阉割而来的),只能用户自己根据项目需求去找一个质量和速度的平衡点。 |
gihu 发表于 2024-7-17 19:35 有收获。顺着看了几个B站的视频,发现磨薄没用,但是开盖很管用。 |
acafeiqq 发表于 2024-7-18 21:04 明年618可以吧 |
gihu 发表于 2024-7-18 20:19 我用的渲染器最多5倍吧,gpu出的效果还是差一点,为了抵消质量差异需要把一些参数开的更高,这会稍微降低一点速度 |
| 9950双11不知道3500够不够。 |
tim6252 发表于 2024-7-17 21:17 是的,现在显卡跑渲染太猛,我觉得你说的3~5倍速度貌似有点保守了。如果不是全程需要双精度浮点,随便一张rtx 4080以上级别的显卡,单精度浮点都是cpu的十倍起跳了 |
gihu 发表于 2024-7-17 20:53 我houdini只用来做毛发模拟,没跑过渲染。 主要用maya这边arnold,从zen1开始吧,到zen1+ zen2 到现在zen3,感觉au对于渲染一直都是线性增加,渲染效率几乎完全=核心数x频率。这次准备越过zen4直接到zen5了,8大核就够了,只跑一下模拟,渲染现在逐渐转到GPU了,8 9成的效果但3-5倍的速度. |
tim6252 发表于 2024-7-17 20:35 是的,houdini的大小核调度异常的事情有听说过,站内有人给过解决方案,不知道你试过没有。AMD的浮点单元效率很早以前就开始优于对手,只在推土机系列出现后落后于对手一段时间。zen出现后重新反超,到现在zen5几乎是全面碾压。 |
gihu 发表于 2024-7-17 13:49 目前intel的大小核跑做特效的统治级软件houdini。。。要么只能全大核,要么只要软件不在最前端就立马变成全小核跑导致速度骤降的问题都还没解决。。。 这个大小核是异构的就是最大的槽点和问题所在,怎么做调度都没用,异构核之间切换很多软件都会有问题 |
本帖最后由 OstCollector 于 2024-7-17 20:14 编辑 Neo_Granzon 发表于 2024-7-17 15:15 system/360 g5、 power 9好像有128bit的浮点 glibc也有相关代码 risc-v也定义了Q扩展 |
rx_78gp02a 发表于 2024-7-17 19:48 哈哈  打错了,应该是2mm多。但顶盖是散热,不是积热。 打错了,应该是2mm多。但顶盖是散热,不是积热。积热的是那两个面积极小的ccd,可能还有那个满是气泡的钎焊层  |
gihu 发表于 2024-7-17 19:35 2CM怕是削穿到主板了吧  。 。意思是那些说顶盖厚积热的一直都在意淫? |
kozaya 发表于 2024-7-17 08:37 这不是看CPU体质能稳多少Boost么...... |
本帖最后由 gihu 于 2024-7-17 20:06 编辑 声色茶马 发表于 2024-7-17 19:13 有人做过测试,顶盖削薄了2mm多,毛用没有 |
| 现在这个封装不是很多人吐槽盖太厚闷罐么? |
lanyer 发表于 2024-7-17 17:33 前面说这个的可能和你不在一个点上,他们是认为没啥应用需要到512位精度,但其实avx512又不仅仅只是提供更高精度计算,还提供更宽的并行常规精度计算。 |
|
说用不到avx512的,怕是不用深度计算,加解密应用,一些网游,,,或者,不玩 ps3模拟器 |
gihu 发表于 2024-7-16 19:10 啊,还有什么指令集能做128bit精度计算?浮点数标准最多就到80位扩展精度,除了科学计算连fp64都用不到。 真要算大数,都是自定数据结构和算法,硬件支持根本没意义。你弄个128bit的乘法器那得多慢啊。 |
af_x_if 发表于 2024-7-17 09:54 x86不到迫不得已是不会砍指令的,对生态信心是严重打击。 |
Neo_Granzon 发表于 2024-7-17 05:56 aida64的测试对avx指令支持很完整,119k支持avx512,你这个跑aida64几乎等同于7G的10700K,可不吊打5.4G的126k |
tim6252 发表于 2024-7-17 04:02 如果是常规桌面端,牙膏的24核心的架构如果大小核全超频,实力还是不容小觑的。但超频后刷刷榜还是得老老实实默频默压使用。毕竟日常使用或者工作环境,那稳定性是第一位的。不过工作站服务器端吗,咋样超都没牙膏什么事了。 |
| 感觉挺厉害的 |
赫敏 发表于 2024-7-17 08:46 我的想法是老指令都TM砍了,只留一套功能不重复的。 至于用上老指令的老应用反正性能需求也不会太高,转译执行也应该流畅。 X86转译ARM效率都七八成了,那AVX转X86下的类SVE凭什么不行。 |
| 关键是功耗比和积热,性能已经不是首要的了。 |
| 所以单核多少分 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-10-11 03:53 , Processed in 0.013391 second(s), 10 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.