|
发布时间: 2025-6-3 14:03
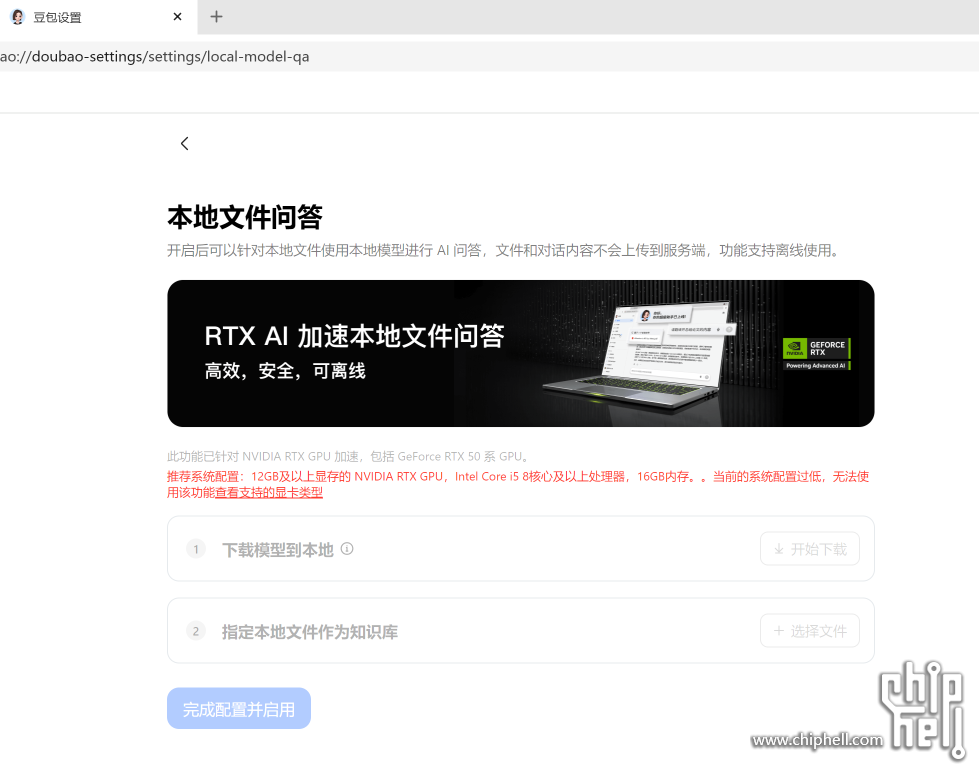
正文摘要:有没有坛友试过了,效果如何,现在用的笔记本,只有核显。 豆包PC版的前端很好用,比lms、chatbox等更方便,免费使用吐字快,准确度也不错。 相信个人以后用这类AI工具的场景会越来越多,N卡的生态优势进一步加强 ... |
powerduke 发表于 2025-6-4 03:21 本地我是接入个人文件夹和笔记 主用ollama作推理框架 obsidian和open webui作为rag的前端 外加langgraph和dify 本地全开源框架的好处是可以随便接mcp server甚至a2a资源 不管公开的还是自己建立的 有问题可以随意调 OpenAI Agents SDK就会麻烦很多 遇到问题就得靠猜 我在gdpr dsa的保护伞下 应该尽量用体量更大的厂商 使用欧区azure deepseek-r1不成问题 白嫖到r2出来都够了 套一层litellm就能兼容大部分前端程序 |
squll009 发表于 2025-6-4 13:58 忽悠花儿街用 |
| 现在cpu带的ai模块到底有什么用? |
我怀疑是用于分摊AI处理的作业的,把用户的显卡纳入了算力节点。  |
YsHaNg 发表于 2025-6-3 22:49 都可以随便聊聊咯,线上线下各有满足的应用场景,本地知识库更像部署的本地分析引擎,差点意思但放心。 谷歌的在线服务一是国内受限要翻,二是比起豆包更不想上传文档过去,当然丑国也限制了deepseek,扯平了。 |
本帖最后由 YsHaNg 于 2025-6-3 14:51 编辑 powerduke 发表于 2025-6-3 13:55 google ai studio白送gemini pro 所以你到底是要讨论在线远程llm还是离线本地部署模型 |
| 目前正常能买到的消费级单卡,哪怕5090,跑32b的模型,和豆包在线版一比也是弱智 |
YsHaNg 发表于 2025-6-3 21:51 目前豆包在线版我觉得挺好用,免费,速度快,准确度够用 |
| 用ollama/vllm不好吗 再配个open webui/cherry studio之类的前端 想改啥改啥 顺手还能接langgraph cline zed之类 被一个前端圈地大可不必 |
a010301208 发表于 2025-6-3 14:44 只是本地知识库把,对企业还是有用处的,改天试试,单位的笔记本灰色的不让部署 |

|
就列出的这些显卡(里面甚至还有6G的),根本跑不了啥东西出来啊,比完整的模型缩水太多了吧? 纯粹是当学习一下基本操作、设置的?  |
| 非RTX也能用 1080ti吃显存然后cpu计算 |
xsdianeht 发表于 2025-6-3 14:14 好像也是,我试过LLM那个ds,问他问题就很弱智。看教程用5090D部署的 但是看那些UP主用的话就很好,不知道什么问题。。 |
击水三千 发表于 2025-6-3 14:05 有教程吗 大佬。 |
|
本地跑就消费级显卡4090和5090也就卡在32B这个级别了吧也不太够用对比其他能本地跑的模型优势可能就多模态? |
|
这个到底是豆包模型本地版,还是用别的模型,要是别的模型整这些干什么,没限制的abliterated版本不好吗。 豆包强调数据和对话内容确实不会上传到服务端,但是你打开联网功能的话你问答的时候他什么都知道,你最好别问一些逆天的内容 |
| 豆包的本地版(显卡能跑得起来),估计毫无悬念被QWQ32B,qwen3 完爆吧 |
| 黑字介绍,应该不在线也可以使用。 |
| 本地部署完后使用需要在线才能使用么 |
|
针对本地知识库进行提问的。 什么12333 12366 一万号 和 银行客服用这个不错 |
| 消费级单卡跑这个基本和弱智无异 |
|
貌似其他llm的本地部署可以直接破甲,没有屏蔽词,不知道豆包本地可不可以 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-6-8 08:43 , Processed in 0.013817 second(s), 10 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.