|
发布时间: 2025-6-13 12:02
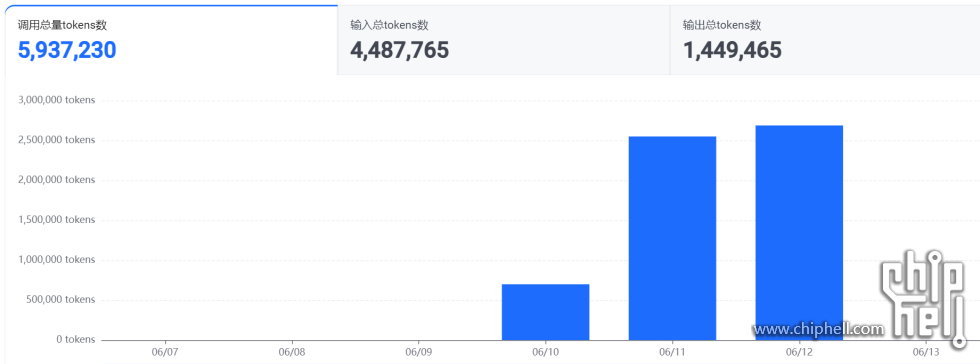
正文摘要:程序python的,主要功能是基于llm的自动的论文抓取、分析、实验、写报告。 在火山引擎花19.9整了2千万tokens的额度,整个跑下来的大体数据: 1. 数据:2篇英文论文全篇 2. llm流程:生成概要、多个agent角色生成多 ... |
pdvc 发表于 2025-6-13 20:35 好吧,告辞 |
powerduke 发表于 2025-6-13 17:18 H200八卡机器价格在200-230左右。 |
|
本帖最后由 neavo 于 2025-6-13 18:07 编辑 火山API的整体优化是吞吐向的而不是延迟向的,可以尝试把任务并行化,几十kt/s的吞吐速度很轻松,可以算是个人账户速度限额给的最宽松的平台了 
|
YsHaNg 发表于 2025-6-13 17:10 基于工作流方式,实际用哪个llm平台影响不太大,目前我的选择标准肯定是哪个便宜快就支持哪个。 |
pdvc 发表于 2025-6-13 14:22 看新闻介绍还是要买nv的专业产品,不知道价格几何 |
| 我选择白嫖一手gemini 现在市场还在早期 过两天就会再送免费高阶额度 上次的azure r1 perplexity pro 够用好久 |
| 本地跑速度在3000-4000t/s,可以试试NIM |
 什么?本地大语言模型不都是为了RP(角色扮演)吗 什么?本地大语言模型不都是为了RP(角色扮演)吗 |
| 本地碰到上下文内容大 就会大量占用显存拖慢速度 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-6-26 22:59 , Processed in 0.009480 second(s), 7 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.