|
发布时间: 2025-6-22 11:17
正文摘要:本帖最后由 PolyMorph 于 2025-6-22 11:28 编辑 RTX 5090 vs RTX 5090 D 性能差异分析 |
PPXG 发表于 2025-6-23 14:49 所以这四位精度,FP4 为代表的大饼rubin ,目前也没看到业界跟上去啊。 反正int4 和 awq的四位简化,实际跑下来确实比FP8的差了不少,就是胜在速度快,并发高 |
blackbeardever 发表于 2025-6-22 14:13 目前推断是驱动级的软件锁,类似于30系LHR,一但监测到大规模低精度矩阵运算就主动降算力,tensorcore物理上应该是没做阉割 |
PPXG 发表于 2025-6-22 13:20 确实是这样 很多模型用6000ada和5000ada看起来也没多少差距 |
| 四月中旬的时候我也测过了,发了帖子https://www.chiphell.com/thread-2688736-1-1.html |
PPXG 发表于 2025-6-22 13:20 主要是FP4的差距,那些测试没区别的都没测FP4性能 |
jaycty 发表于 2025-6-22 13:17 我买了,主要是有保修,不过如果真的弟也禁了,就不知道了。。。 |
|
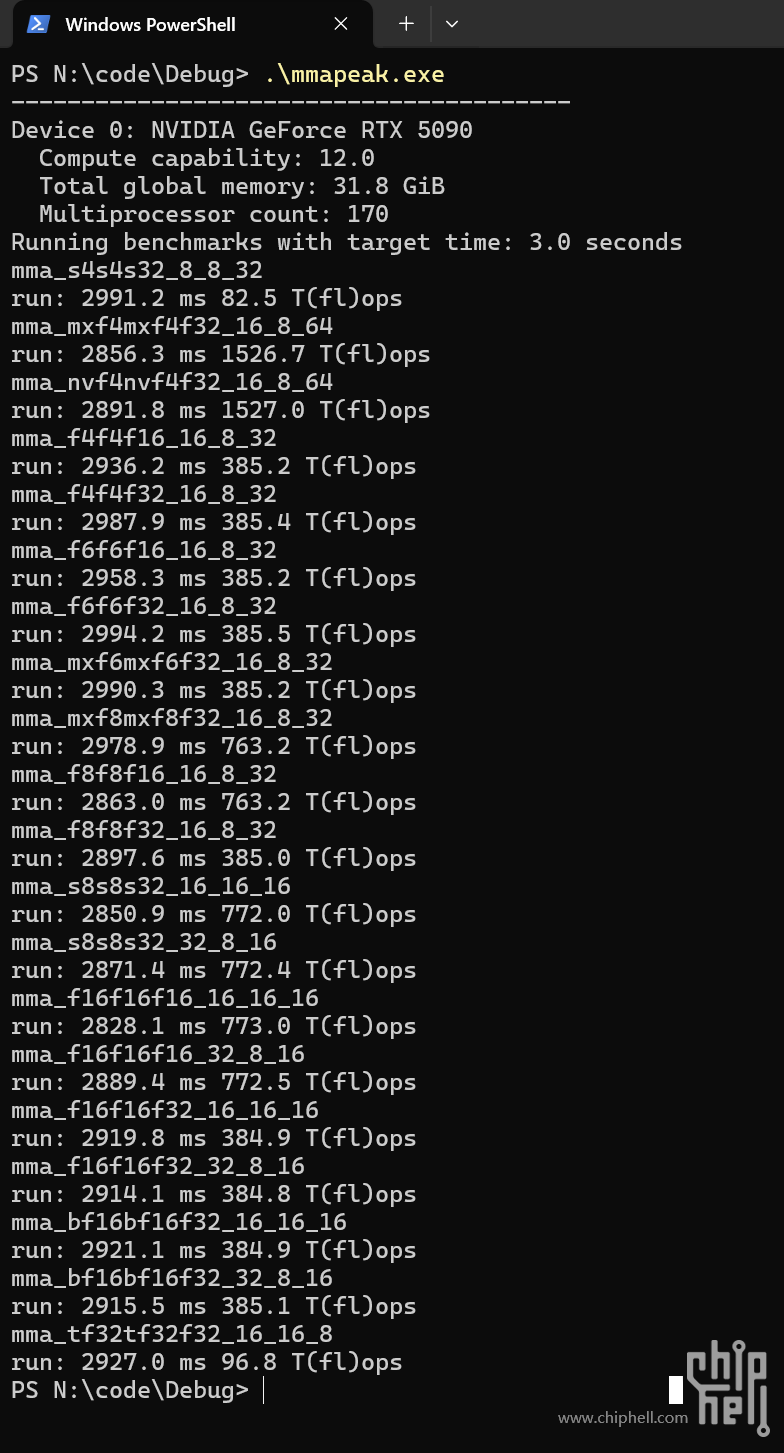
把手头的卡都大致测了一下,和5090&5090D做了对比,理论计算性能差距还是比较大的,除了mma_s4s4s32_8_8_32这个整数矩阵,50系是倒退严重啊! RTX3070 VS RTX5090(D) VS RTX4070TI VS RTX3090 mma_s4s4s32_8_8_32 run: 2801.6 ms 308.0 T(fl)ops 82.5 T(fl)ops(79.6) 583.0 T(fl)ops 491.3 T(fl)ops mma_f8f8f16_16_8_32 run: 2968.0 ms 763.2 T(fl)ops(430.2) 321.3 T(fl)ops mma_f8f8f32_16_8_32 run: 2978.7 ms 385.0 T(fl)ops(370 ) 169.8 T(fl)ops mma_s8s8s32_16_16_16 run: 2999.8 ms 169.9 T(fl)ops 772.0 T(fl)ops(430.9) 332.6 T(fl)ops 294.3 T(fl)ops mma_s8s8s32_32_8_16 run: 2999.4 ms 170.0 T(fl)ops 772.4 T(fl)ops(430.9) 332.6 T(fl)ops 294.3 T(fl)ops mma_f16f16f16_16_16_16 run: 3000.0 ms 86.4 T(fl)ops 773.0 T(fl)ops(428.9) 170.4 T(fl)ops 152.4 T(fl)ops mma_f16f16f16_32_8_16 run: 3000.1 ms 86.4 T(fl)ops 772.5 T(fl)ops(429.7) 170.4 T(fl)ops 151.7 T(fl)ops mma_f16f16f32_16_16_16 run: 2999.4 ms 43.2 T(fl)ops 384.9 T(fl)ops(367.4) 85.3 T(fl)ops 76.4 T(fl)ops mma_f16f16f32_32_8_16 run: 2996.1 ms 43.2 T(fl)ops 384.8 T(fl)ops(372.0) 85.3 T(fl)ops 76.1 T(fl)ops mma_bf16bf16f32_16_16_16 run: 2997.0 ms 43.1 T(fl)ops 384.9 T(fl)ops(371.6) 85.1 T(fl)ops 75.7 T(fl)ops mma_bf16bf16f32_32_8_16 run: 2997.1 ms 43.1 T(fl)ops 385.1 T(fl)ops(371.8) 85.1 T(fl)ops 76.1 T(fl)ops mma_tf32tf32f32_16_16_8 run: 2999.8 ms 21.6 T(fl)ops 96.8 T(fl)ops(93.5) 42.6 T(fl)ops 37.9 T(fl)ops 括号内红色标识为5090D。 |
| 我确实不理解为什么要买5090弟弟 |
不管D不D的 其实5楼的答案 就是目前的最终答案了 |
chm128256 发表于 2025-6-22 21:57 继续跑了下3090的,发现理论能力还不如4070ti啊,就剩显存大这个优势了。 
|
4070ti也跑了下,对比一下和5090差距大不大,不过很多运算指令集都不支持啊。是50系独家秘笈吧?
|
| 路过问一下 某鱼上看 4090d 48g 便宜那么多 有什么限制呢 ,不能多卡 推理吗 ? |
|
本帖最后由 chm128256 于 2025-6-22 22:51 编辑 RTX3070 VS RTX5090(D) VS RTX4070TI mma_s4s4s32_8_8_32 run: 2801.6 ms 308.0 T(fl)ops 82.5 T(fl)ops(79.6 T(fl)ops) 583.0 T(fl)ops mma_f8f8f16_16_8_32 run: 2968.0 ms 763.2 T(fl)ops(430.2) 321.3 T(fl)ops mma_f8f8f32_16_8_32 run: 2978.7 ms 385.0 T(fl)ops(370 ) 169.8 T(fl)ops mma_s8s8s32_16_16_16 run: 2999.8 ms 169.9 T(fl)ops 772.0 T(fl)ops(430.9) 332.6 T(fl)ops mma_s8s8s32_32_8_16 run: 2999.4 ms 170.0 T(fl)ops 772.4 T(fl)ops(430.9) 332.6 T(fl)ops mma_f16f16f16_16_16_16 run: 3000.0 ms 86.4 T(fl)ops 773.0 T(fl)ops(428.9) 170.4 T(fl)ops mma_f16f16f16_32_8_16 run: 3000.1 ms 86.4 T(fl)ops 772.5 T(fl)ops(429.7) 170.4 T(fl)ops mma_f16f16f32_16_16_16 run: 2999.4 ms 43.2 T(fl)ops 384.9 T(fl)ops(367.4) 85.3 T(fl)ops mma_f16f16f32_32_8_16 run: 2996.1 ms 43.2 T(fl)ops 384.8 T(fl)ops(372.0) 85.3 T(fl)ops mma_bf16bf16f32_16_16_16 run: 2997.0 ms 43.1 T(fl)ops 384.9 T(fl)ops(371.6) 85.1 T(fl)ops mma_bf16bf16f32_32_8_16 run: 2997.1 ms 43.1 T(fl)ops 385.1 T(fl)ops(371.8) 85.1 T(fl)ops mma_tf32tf32f32_16_16_8 run: 2999.8 ms 21.6 T(fl)ops 96.8 T(fl)ops(93.5) 42.6 T(fl)ops 括号内红色标识为5090D。 |
FYI: TEST IN ubuntu 24.04.2LTS

|
| 生产力的价值会升值 而娱乐会贬值。。。 |
| 肯定买5090啊,和4090一个道理。 |
|
我买5090没买D的原因就是以后卖了90肯定比90D更值钱 其实我只用来跑游戏而已 |
| 有些买了D的人心如刀绞 |
| 满意离开 |
我确实不理解为什么要买5090弟弟 |
jaycty 发表于 2025-6-22 13:17 因为有保修,而且不是所有人买5090都是为了跑ai |
xjr12000 发表于 2025-6-22 13:10 应该是因为显存带宽限制根本跑不到理论性能。 所有没区别。 |
| 这跑分差不多翻倍的差距远大于硬件的差别,有点离谱啊。会不会是驱动或者固件上做的手脚? |
xjr12000 发表于 2025-6-22 13:10 你好,是的 |
本帖最后由 PPXG 于 2025-6-22 13:23 编辑 xjr12000 发表于 2025-6-22 13:10 早就能测出来区别了,有些人测出来没区别主要是因为现阶段绝大多数跑推理和训练的通用模型瓶颈压根不在这里,所以老黄哪怕阉割了也很难在实际的时间成本上显现出来差距 说白了就是,现在跑模型的瓶颈压根不在tensorcore |
| 我确实不懂为什么要买5090弟 |
|
这是不是屯卡的卖不掉了,所以出来打广告吗? 之前3月份的测试是没有任何区别 |
| 高端卡 算力 和普通人关系不大了 |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-7-10 16:05 , Processed in 0.014519 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.