|
发布时间: 2025-8-13 22:46
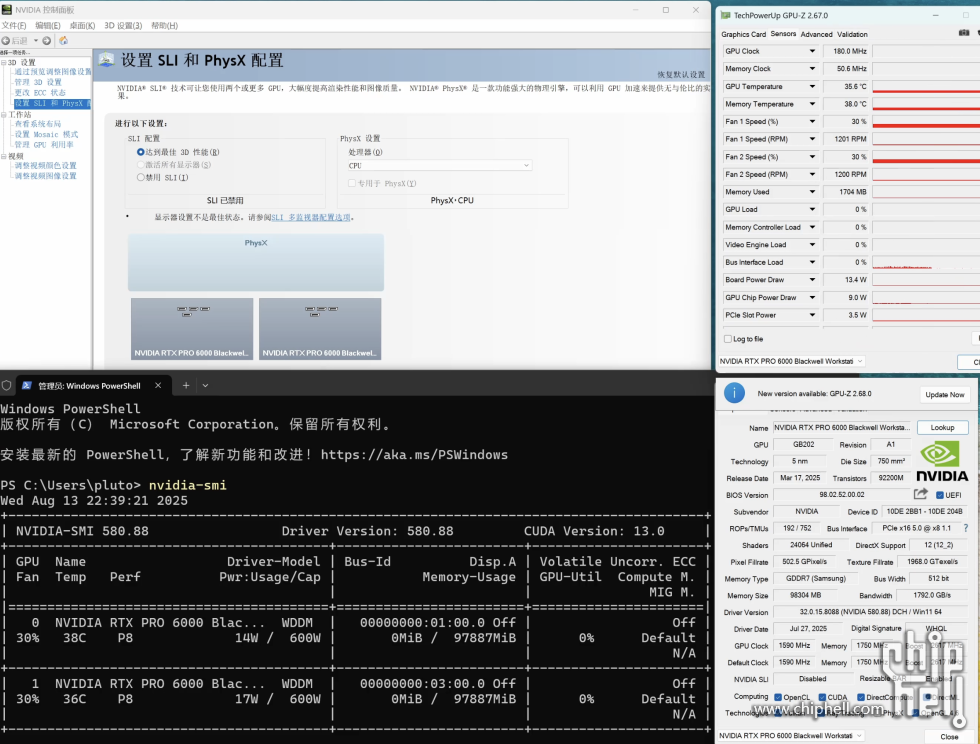
正文摘要:本帖最后由 godspeed66 于 2025-8-13 23:30 编辑 可惜没有SLI接口,估计是驱动错误导致的异常显示 |
|
直接PCIE5.0? |
| 请问这张咭可以玩stable diffusion吗? |
zhuifeng88 发表于 2025-8-14 23:19 万分感谢 |
本帖最后由 zhuifeng88 于 2025-8-14 23:32 编辑 godspeed66 发表于 2025-8-14 21:04 sm120的nvfp4目前只做了dense, 没做MoE, moe急着用可以自己从sm100的抄一份改改, 只是跑起来的话修改量估摸着100行左右吧, 就改一下cutlass部分的模板参数就行 还有你用的nvfp4模型格式不对, vllm透明支持的是compressed tensors格式的和比较新版本optimum-nvidia出的, 老的你得自己处理下 |
zhuifeng88 发表于 2025-8-14 16:36 改CUDA有用 FP8 可以了 但FP4报错 vllm serve /home/Qwen3-235B-A22B-Thinking-2507-FP4 --served-model-name Qwen3-235B-A22B-Thinking-2507-FP4 --max-model-len 201000 --tensor-parallel-size 2 --gpu-memory-utilization 0.9 (APIServer pid=15764) INFO 08-14 20:58:03 [api_server.py:1805] vLLM API server version 0.10.1.dev628+g00e3f9da4.d20250814 (APIServer pid=15764) Value error, Unknown quantization method: . Must be one of ['aqlm', 'awq', 'deepspeedfp', 'tpu_int8', 'fp8', 'ptpc_fp8', 'fbgemm_fp8', 'modelopt', 'modelopt_fp4', 'marlin', 'bitblas', 'gguf', '**q_marlin_24', '**q_marlin', '**q_bitblas', 'awq_marlin', '**q', 'compressed-tensors', 'bitsandbytes', 'qqq', 'hqq', 'experts_int8', 'neuron_quant', 'ipex', 'quark', 'moe_wna16', 'torchao', 'auto-round', 'rtn', 'inc', 'mxfp4']. [type=value_error, input_value=ArgsKwargs((), {'model': ...attention_dtype': None}), input_type=ArgsKwargs] (APIServer pid=15764) For further information visit https://errors.pydantic.dev/2.11/v/value_error |
zhuifeng88 发表于 2025-8-14 16:36 感谢 我试试 |
godspeed66 发表于 2025-8-14 16:12 不要用wsl,Linux下直接装驱动然后拉配好的docker跑,性能和吞吐应该会强老大一截了 |
本帖最后由 zhuifeng88 于 2025-8-14 17:00 编辑 godspeed66 发表于 2025-8-14 16:12 toolkit不要用cuda13, 用12.8.1 ====== 实在搞不定建议用docker去处理build算了 ``` https://github.com/vllm-project/vllm/blob/main/docker/Dockerfile ``` 把里面所有12.0改成12.0a就行了 |
zhuifeng88 发表于 2025-8-14 13:18 raise CalledProcessError(retcode, cmd) subprocess.CalledProcessError: Command '['cmake', '/home/vllm06/vllm', '-G', 'Ninja', '-DCMAKE_BUILD_TYPE=RelWithDebInfo', '-DVLLM_TARGET_DEVICE=cuda', '-DVLLM_PYTHON_EXECUTABLE=/root/anaconda3/envs/vllm06/bin/python3.12', '-DVLLM_PYTHON_PATH=/root/anaconda3/envs/vllm06/lib/python312.zip:/root/anaconda3/envs/vllm06/lib/python3.12:/root/anaconda3/envs/vllm06/lib/python3.12/lib-dynload:/root/anaconda3/envs/vllm06/lib/python3.12/site-packages:/home/vllm06/transformers/src:/root/anaconda3/envs/vllm06/lib/python3.12/site-packages/setuptools/_vendor', '-DFETCHCONTENT_BASE_DIR=/home/vllm06/vllm/.deps', '-DNVCC_THREADS=1', '-DCMAKE_JOB_POOL_COMPILE:STRING=compile', '-DCMAKE_JOB_POOLS:STRING=compile=32', '-DCMAKE_CUDA_COMPILER=/usr/local/cuda-13.0/bin/nvcc']' returned non-zero exit status 1. [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building editable for vllm Failed to build vllm ERROR: Failed to build installable wheels for some pyproject.toml based projects (vllm) 放弃了。等软件生态完善吧 4090 RTX 6000ADA 都没遇到这类问题 |
本帖最后由 deepfishing 于 2025-8-14 15:39 编辑 godspeed66 发表于 2025-8-14 11:02 wsl。。。。 建议老老实实实体机装Linux,wsl没吊用,win下nccl从来没做过支持,wsl下也不会工作,至于Linux下,反正当年早期4090or6000ada nccl都不正常,现在这玩意通信有问题也不奇怪,适配要是全弄好稳定了,公司应该开始扫货了 |
| 6W多的显卡 做梦都不敢想 |
godspeed66 发表于 2025-8-14 11:27 "vllm 0.10.1.dev166+g04e38500e.d20250729.cu129 /home/vllm02/vllm" 你用的source版本太老了, 0.10.1.dev166 commit id是04e38500eeaa683f107fc16011aee65981afc6cd sm120的fp8支持是你这个commit之后287个commit 3303f134e03f7a80b42e50065976be9d499c8683合并的 |
godspeed66 发表于 2025-8-14 10:28 我的理解是开启sli才开启p2p,可以跑一下p2plantency测试一下peer to peer的带宽看,那是提升这么明显有点没想到 |
godspeed66 发表于 2025-8-14 11:27 这是 vLLM / PyTorch 在 Blackwell(RTX 50 系列 / SM100)上的 FP8 block-scaled GEMM 还没实现 导致的——不是你的命令写错了。 要点👇 Qwen 的 FP8 权重是 block-wise(MXFP8)缩放;vLLM 会走 scaled_mm/CUTLASS 的 “block-scaled FP8 GEMM” 路径。Blackwell 这一路径目前在 vLLM / PyTorch 的实现上缺失或被禁用,所以直接抛出:Currently, block scaled fp8 gemm is not implemented for Blackwell。 GitHub Qwen TensorRT-LLM 侧也有类似反馈:Blackwell 暂不支持 FP8 block-scaled GEMM(同类错误/不支持提示)。这说明是生态层面的缺口,不是你机器环境的问题。 GitHub 硬件本身具备 FP8/子字节算力(CUTLASS 文档已写明 Blackwell 的新 UMMA/tcgen05 指令支持 4/6/8bit 浮点及缩放),但上层库要把这些内核打通才能用,你现在用到的 nightly 组合还没接上。 NVIDIA Docs Colfax Research 可行的绕过方案(按稳妥程度排序) 改用 4bit 权重量化(**Q / AWQ) 这不依赖 FP8 内核,vLLM 已支持,Blackwell 上可直接跑。 官方 **Q(INT4)仓库:Qwen/Qwen3-30B-A3B-**Q-Int4。 vllm serve Qwen/Qwen3-30B-A3B-**Q-Int4 \ --quantization marlin \ --tensor-parallel-size 2 \ --max-model-len 65536 \ --dtype half (--quantization marlin 是 vLLM 跑 **Q 的推荐后端) Hugging Face GitHub VLLM Docs 第三方 AWQ(INT4):cpatonn/Qwen3-30B-A3B-Thinking-2507-AWQ vllm serve cpatonn/Qwen3-30B-A3B-Thinking-2507-AWQ \ --quantization awq \ --tensor-parallel-size 2 \ --max-model-len 65536 (AWQ/**Q 在 vLLM 上均可用;注意第三方权重质量与许可) Hugging Face VLLM Docs 提示:你现在的 --max-model-len 201000 对 2×16 GB 来说 KV Cache 会非常吃显存,先降到 32K~64K 更现实,后续再调优。 换用 BF16/FP16 原始权重(不推荐在 2×16 GB 上) BF16 30B 级别需要 ~60 GB 以上显存,仅供有大显存(或 NVLink 多卡、或强力 CPU/磁盘 offload)时考虑。可以用: vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 \ --dtype bfloat16 \ --tensor-parallel-size 2 \ --max-model-len 32768 (多数 30B MoE BF16 在 32 GB 显存下仍然吃紧,实际不适合你当前 2×16 GB) Hugging Face 改后端尝试 Transformers+TransformerEngine(实验性) NVIDIA TransformerEngine 声称支持到 Blackwell,但社区仍有“细粒度/块缩放 FP8”在新架构上的问题反馈;能跑与否取决于具体版本组合(驱动/CUDA/TE/PyTorch)。若要尝试,请走最新 TE + 官方示例(注意是实验性)。 NVIDIA Docs +1 Hugging Face |
我輩樹である 发表于 2025-8-14 11:44 pro 6000 不需要破解的, 本来就是官方支持的, 只要把bios的pcie安全相关的功能禁用掉一部分就能通 |
godspeed66 发表于 2025-8-14 11:02 而且我不知道你是怎么做到24.04编译过没法运行的...我这一点问题都没有 
|
| 支持cpu转发的互联本来就没问题(消耗cpu资源手动自己分,nv不会拦着你),只是没有nvlink桥的不支持p2pdirect,目前就只有tinygrad在做这方面的破解,但应该是没开源的,开源的到40系。 |
godspeed66 发表于 2025-8-14 10:12 是的,目前几个框架对Blackwell的FP8兼容性很差。建议用TensorRT-LLM跑NVFP4 量化,开张量并行速度起飞 |
zhuifeng88 发表于 2025-8-14 10:38 跑不起来 RuntimeError: Worker failed with error 'Currently, block scaled fp8 gemm is not implemented for Blackwell', please check the stack trace above for the root cause torch 2.9.0.dev20250729+cu129 torchaudio 2.8.0.dev20250729+cu129 torchvision 0.24.0.dev20250729+cu129 transformers 4.55.0.dev0 /home/vllm02/transformers triton 3.3.1 vllm 0.10.1.dev166+g04e38500e.d20250729.cu129 /home/vllm02/vllm vllm serve /root/.cache/modelscope/hub/models/Qwen/Qwen3-30B-A3B-Thinking-2507-FP8 --served-model-name Qwen3-30B-A3B-Thinking-2507-FP8 --max-model-len 201000 --tensor-parallel-size 2 --gpu-memory-utilization 0.9 |
老司机dd 发表于 2025-8-14 10:33 wsl环境下 22.04,不要24.04 这个卡理论上支持P2P,但我在WSL下P2P测试失败 ubuntu下 22.04没安上显卡驱动,24.04 下vllm 编译成功但无法运行。。。。。。等驱动和软件生态继续完善吧 |
godspeed66 发表于 2025-8-14 10:28 有点儿意思啊,感觉像是官方的P2P link |
|
本帖最后由 PolyMorph 于 2025-8-14 10:44 编辑 比6090默认还高 |
deepfishing 发表于 2025-8-14 10:36 sm120的fp8和nvfp4都已经做好了啊 https://github.com/vllm-project/vllm/pull/22131 https://github.com/vllm-project/vllm/pull/21309 |
KimmyGLM 发表于 2025-8-14 10:20 新卡硬件换了,fp8支持还没做好,fp8实现高度绑定硬件吧 |
| 提前使用 RTX 6090啊~~ |
godspeed66 发表于 2025-8-14 10:28 Windows下运行的吗,Linux下怎么开启和禁用呢?不带NVLink的SLI,难道是Driect P2P ?! |
KimmyGLM 发表于 2025-8-14 10:20 root/.cache/modelscope/hub/models/tclf90/Qwen3-235B-A22B-Thinking-2507-AWQ --served-model-name Qwen3-235B-A22B-Thinking-2507-AWQ --max-model-len 231000 --tensor-parallel-size 2 --gpu-memory-utilization 0.9 开不开SLI 都是 张量,开启SLI后性能的增强,应该与兼容性有关吧。因为单卡跑32B-awq单线程60t/s,多线程2500t/s;跑32B-awq双卡VLLM 不开启SLI ,只有45~49t/s; 而双卡VLLM 不开启SLI Qwen3-235B-A22B-Thinking-2507-AWQ只有25-35,但开启SLI后能有45~60t/s; |
本帖最后由 KimmyGLM 于 2025-8-14 10:22 编辑 godspeed66 发表于 2025-8-14 10:12 那看来SLI 功能相当于是张量并发?提升这么多啊 另外,为啥6000pro 会不支持FP8啊? |
本帖最后由 godspeed66 于 2025-8-14 10:15 编辑 港城钢铁侠 发表于 2025-8-14 09:41 只能跑 Qwen3-235B-A22B-Thinking-2507-AWQ; 没开启SLI之前,只有25~35t/s的速度,开启SLI之后45~60t/s的速度 RTX PRO 6000不支持现有FP8:block scaled fp8 gemm is not implemented for Blackwell; 跑Qwen3-235B FP8 需要240GB显存才能启动,需要300G显存才能有上下文长度。192GB跑不起来 (APIServer pid=897) INFO 08-14 10:12:26 [async_llm.py:273] Added request chatcmpl-c6c39093434d4044875d5eb0f507e969. (APIServer pid=897) INFO 08-14 10:12:34 [loggers.py:123] Engine 000: Avg prompt throughput: 225.5 tokens/s, Avg generation throughput: 34.4 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 1.1%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:12:44 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 47.6 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 1.3%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:12:54 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 58.2 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 1.5%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:13:04 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 54.8 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 1.7%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:13:14 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 46.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 1.9%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:13:24 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 53.5 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.1%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:13:34 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 54.1 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 10.3% (APIServer pid=897) INFO 08-14 10:13:44 [loggers.py:123] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 53.6 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.5%, Prefix cache hit rate: 10.3% |
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-8-31 04:12 , Processed in 0.012763 second(s), 9 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.