本帖最后由 T.JOHN 于 2023-2-24 09:37 编辑
老样子,正确排版在此
接 前回CUDA环境部署和性能测试,此教程为部署Katago,目前最流行的开源AI围棋软件。完成后你可以出租算力供学棋的人士使用,也可以用于培养自家孩子等,如此让AI走进人们生活,变得更加实用。
围棋AI软件分为前端和后端,Katago是后端,作为开源软件,依旧在积极更新。国内两大围棋AI,星阵抄的就是它,绝艺也不如它,而参加AI围棋大赛的普遍多为Katago魔改。
目前Katago能够充分调用8卡3090/4090,运行模式堪比当年7970挖比特币。与之前那篇文章的AI性能测试程序大相径庭,Katago只占500M显存不到,但核心却是火力全开,永远拉满TDP
这里给一个Katago gpu benchmark,来自 github,以TensorRT为后端的结果如下(忽略1080ti,它没tensor core) 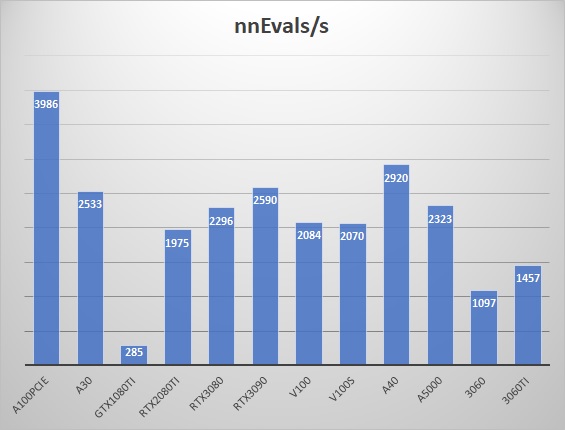
可见拥有大量电阻丝的A100远超3090,这意味着什么?那就是4090 450w~600w的TDP终有用武之地!我相信此时90T的算力可以火力全开,充分利用,绝对不再喂狗!而改进过的tensor core更是可以大放异彩
实战中8卡3090对阵单卡3090即可吊打,可以充分满足土豪的优越感,有了胜负之后不再像3Dmark这种跑分软件空有数字,让人虚空而食之无味。
katago于2023年1月6日发布了1.12.x版本 - 增加了对新的和改进的神经网络架构的支持
- 新增B18C384权重。相比之前的权重如b40c256和b60c320,现在这个b18c384权重强度和b60c256强度差不多,但速度甚至和b40c256差不多块
- 这里稍微普及下权重概念,就是函数的系数。目前AI干的活本质就是y=kx+b的矩阵乘法,k和b就是系数。b是block,c是channel。
- 训练工具从tensorflow换成了pytorch
显然虽然alpha GO/Zero已经退役了,但围棋AI并没有停止发展,而是继续前行,配合强大的算力,水平也越来越高。根据katago 官网的权重,目前最强的权重elo可达13.5k+,而2020年时不过4-5k的样子。这个数字官方虽然称和其他软件及人类没可比性,但也可以参考。目前人类最强棋手申真胥的elo为3800-3900,也是除轩工智能外下棋最接近AI的人。为了让大家对elo有更直接的概念,大致上elo差200,对弈的胜率大概就是82~91开。电子竞技游戏普遍采取这种算法,比如魔兽世界竞技场。
除了Katago这个后端,我们还需要一个前端,Katago官网推荐的有KaTrain和Lizzie等。国内有人魔改了lizzie,功能更强大,也更友善易用,同样发布在 github上,我将以他的版
本为例作为部署教程的前端 Katago安装和调优
- 由于katago的预编译二进制未必匹配你的系统环境,比如它需要libzip5,debian11上只有libzip4。CUDA版本和TensorRT版本也未必对的上,因此编译安装以获取最强性能。这里参考官方手册
- 先安装cmake和git
apt install cmake git - 克隆仓库,获取源代码
git clone https://github.com/lightvector/KataGo.git - 进入编译目录
cd KataGo/cpp - 使用tensorrt
cmake . -DUSE_BACKEND=tensorrt -DCMAKE_CXX_FLAGS='-march=native'
其他编译选项:-DUSE_BACKEND=OPENCL以opencl编译,A卡和10系以前卡的福音。-DUSE_BACKEND=EIGEN这个是CPU专用。-DUSE_TCMALLOC=1使用google开发的内存管理替代系统管理。-DBUILD_DISTRIBUTED=1贡献自己的数据给公众。-DUSE_AVX2=1启用AVX2。我用-march=native替代了avx2,根据本机CPU支持的指令集自适应识别。 - 开始编译,等待一段时间后katago就是最后得到的二进制文件,需要和权重文件及配置文件放在一起配合使用
Make
- 从github上下载预训练的权重 B**C***xxx.bin.gz
- 从github上下载预编译的二进制压缩包katago-v1.1x.x-***.zip,并提取配置文件default_gtp.cfg
- 测试并且调优,输入以下命令跑分
./katago benchmark -model b18c384nbt-uec.bin.gz
得到如下结果,其中nnEvals就是跑分的速度,并根据它推荐的线程数量,在defualt_gtp.cfg中修改为相同的数值,比如本例为
Ordered summary of results:
numSearchThreads = 5: 10 / 10 positions, visits/s = 768.55 nnEvals/s = 654.13 nnBatches/s = 262.88 avgBatchSize = 2.49 (10.5 secs) (EloDiff baseline)
numSearchThreads = 10: 10 / 10 positions, visits/s = 1370.05 nnEvals/s = 1143.12 nnBatches/s = 231.34 avgBatchSize = 4.94 (5.9 secs) (EloDiff +204)
numSearchThreads = 12: 10 / 10 positions, visits/s = 1520.07 nnEvals/s = 1265.04 nnBatches/s = 213.75 avgBatchSize = 5.92 (5.3 secs) (EloDiff +240)
numSearchThreads = 16: 10 / 10 positions, visits/s = 1478.80 nnEvals/s = 1283.18 nnBatches/s = 163.62 avgBatchSize = 7.84 (5.5 secs) (EloDiff +222)
numSearchThreads = 20: 10 / 10 positions, visits/s = 1668.26 nnEvals/s = 1449.97 nnBatches/s = 148.65 avgBatchSize = 9.75 (4.9 secs) (EloDiff +262)
numSearchThreads = 24: 10 / 10 positions, visits/s = 1649.51 nnEvals/s = 1453.94 nnBatches/s = 124.69 avgBatchSize = 11.66 (5.0 secs) (EloDiff +251)
numSearchThreads = 32: 10 / 10 positions, visits/s = 1835.77 nnEvals/s = 1658.07 nnBatches/s = 107.82 avgBatchSize = 15.38 (4.5 secs) (EloDiff +281)
numSearchThreads = 40: 10 / 10 positions, visits/s = 1879.08 nnEvals/s = 1722.75 nnBatches/s = 89.39 avgBatchSize = 19.27 (4.5 secs) (EloDiff +279)
numSearchThreads = 48: 10 / 10 positions, visits/s = 1885.12 nnEvals/s = 1761.32 nnBatches/s = 76.42 avgBatchSize = 23.05 (4.5 secs) (EloDiff +268)
numSearchThreads = 64: 10 / 10 positions, visits/s = 1931.60 nnEvals/s = 1849.76 nnBatches/s = 61.38 avgBatchSize = 30.14 (4.4 secs) (EloDiff +256)
numSearchThreads = 80: 10 / 10 positions, visits/s = 1938.04 nnEvals/s = 1898.51 nnBatches/s = 49.97 avgBatchSize = 38.00 (4.5 secs) (EloDiff +234)
Based on some test data, each speed doubling gains perhaps ~250 Elo by searching deeper.
Based on some test data, each thread costs perhaps 7 Elo if using 800 visits, and 2 Elo if using 5000 visits (by making MCTS worse).
So APPROXIMATELY based on this benchmark, if you intend to do a 5 second search:
numSearchThreads = 5: (baseline)
numSearchThreads = 10: +204 Elo
numSearchThreads = 12: +240 Elo
numSearchThreads = 16: +222 Elo
numSearchThreads = 20: +262 Elo
numSearchThreads = 24: +251 Elo
numSearchThreads = 32: +281 Elo (recommended)
numSearchThreads = 40: +279 Elo
numSearchThreads = 48: +268 Elo
numSearchThreads = 64: +256 Elo
numSearchThreads = 80: +234 Elo
If you care about performance, you may want to edit numSearchThreads in default_gtp.cfg based on the above results!
If you intend to do much longer searches, configure the seconds per game move you expect with the '-time' flag and benchmark again.
If you intend to do short or fixed-visit searches, use lower numSearchThreads for better strength, high threads will weaken strength.
If interested see also other notes about performance and mem usage in the top of default_gtp.cfg
2023-01-18 19:54:40+0800: GPU -1 finishing, processed 32333 rows 1243 batches
Lizzie安装和调优
从 github上 下载 lizzie others system w/o engine.zip 这里我们已经有引擎,所以下载无引擎版本即可
- 下载预编译包解压后,进入软件目录,在终端中输入下面命令即可打开
java -jar lizzie-yzy2.5.1-shaded.jar - 初始化引擎,如果lizzie-yzy2.5.1-shaded.jar和katago及其配置文件和权重放在同一文件夹下,输入如下参数即可导入katago引擎
./katago gtp -model b18cd384nbt-uec.bin.gz -config default_gtp.cfg
 - 参数调优,虽然之前我们设置了KatagonumSearchThreads = 32,但这里未能生效,需要修改lizzie的设置,生效后可以显著提高标题栏上的每秒搜索数量
设置 -> Katago引擎高级参数 -> 设置成32

至此我们已经完成全部操作,你可以开始和AI对弈,也可以试将棋谱导入Katago进行分析,ENJOY!
根据我5G 12400(900元CPU)及240w RTX3070(2000元的显卡)的测试,每秒搜索量为2k~2.5k,如果每步100k计算量,分析/复盘350手棋加起来约耗时4小时14分钟
最后,随着AI时代来临,推荐这篇文章很好的阐述了现在棋士们的心声,为何李世石选择退役,柯洁也不再勤奋。
下一篇文章可能是 "AI画图",懂得都懂
下下偏文章可能是 "AI换脸",懂得都懂 |  310112100042806
310112100042806


 发表于 2023-1-20 21:13
发表于 2023-1-20 21:13

