|
22941| 36
|
[存储] 基于PVE Ceph集群搭建(二):Ceph存储池搭建与基本性能测试 |
评分 | ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
| ||
Archiver|手机版|小黑屋|Chiphell
( 沪ICP备12027953号-5 ) 310112100042806
310112100042806

GMT+8, 2025-12-11 04:04 , Processed in 0.012715 second(s), 6 queries , Gzip On, Redis On.
Powered by Discuz! X3.5 Licensed
© 2007-2024 Chiphell.com All rights reserved.

 发表于 2023-1-12 11:10
发表于 2023-1-12 11:10
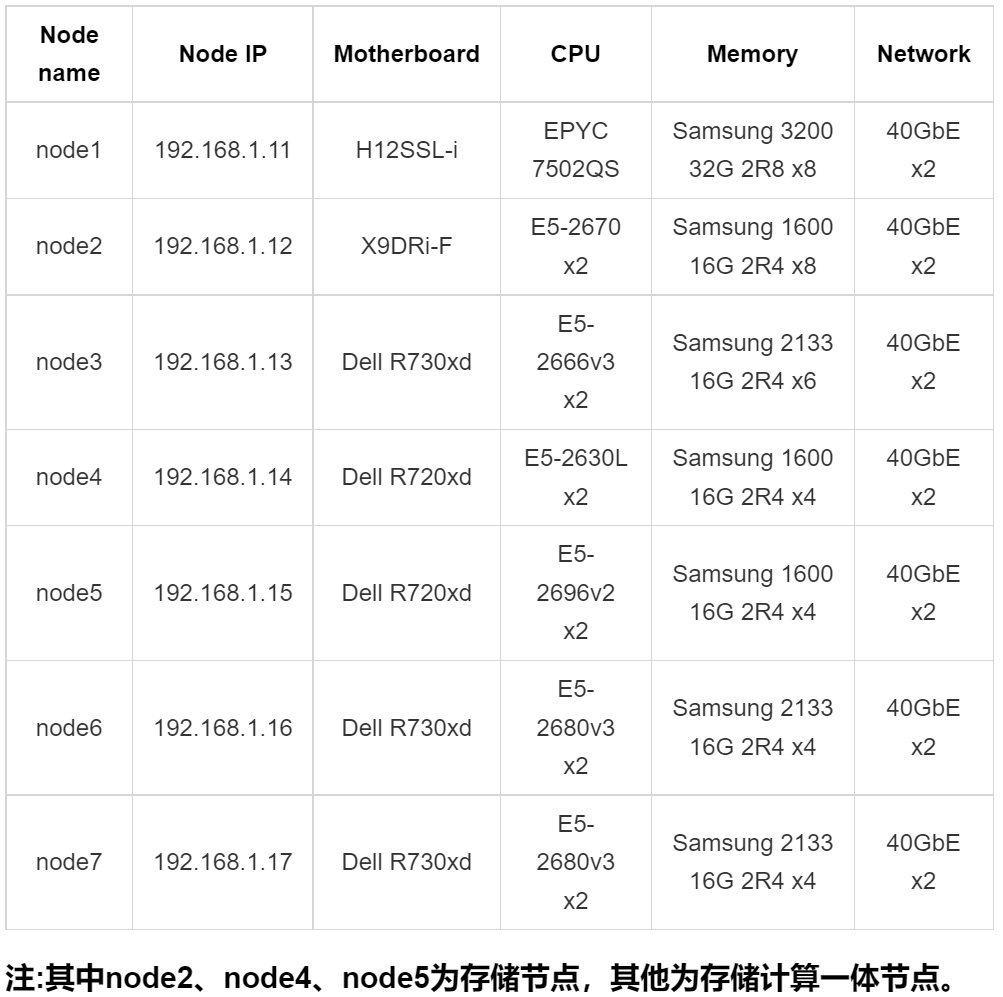
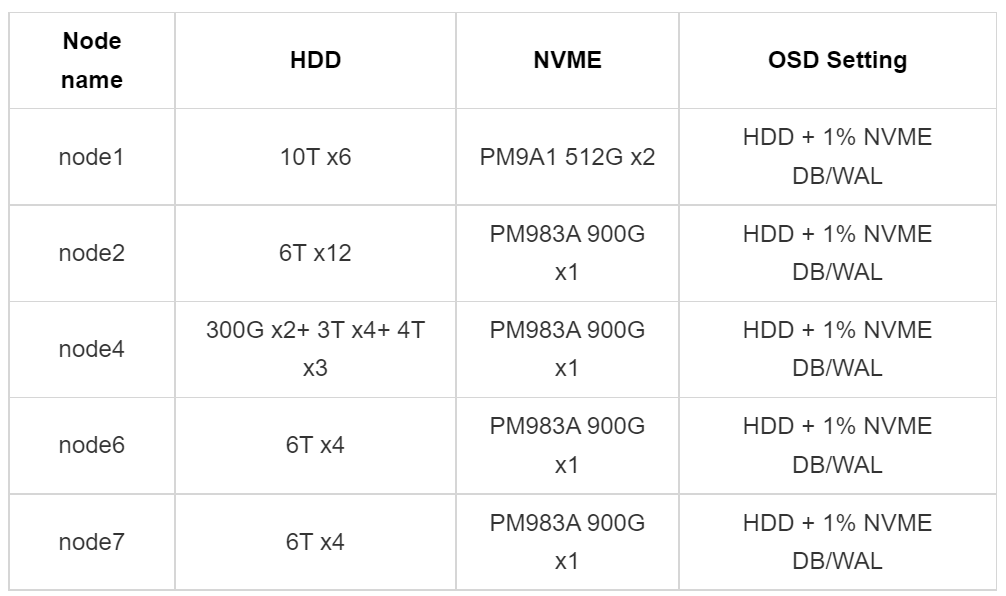
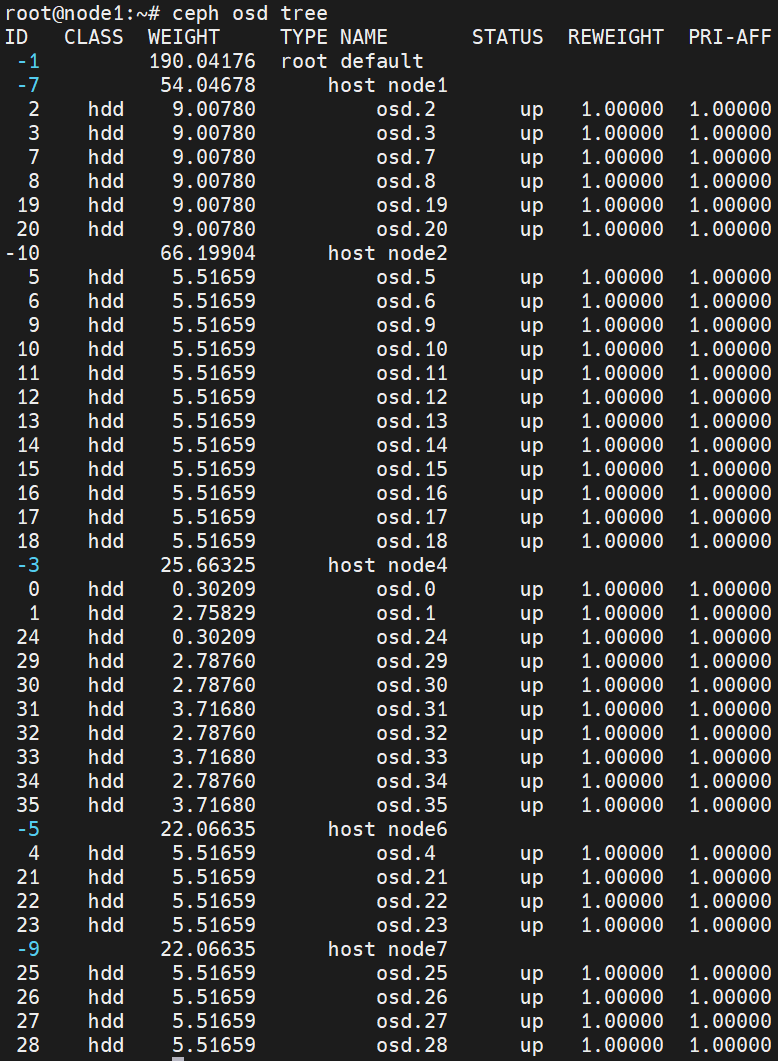
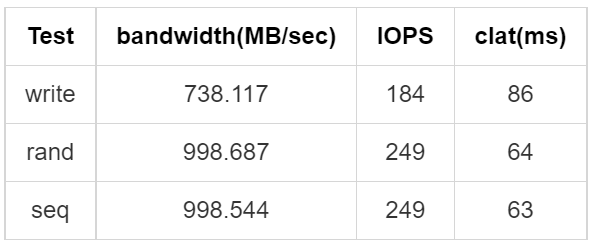
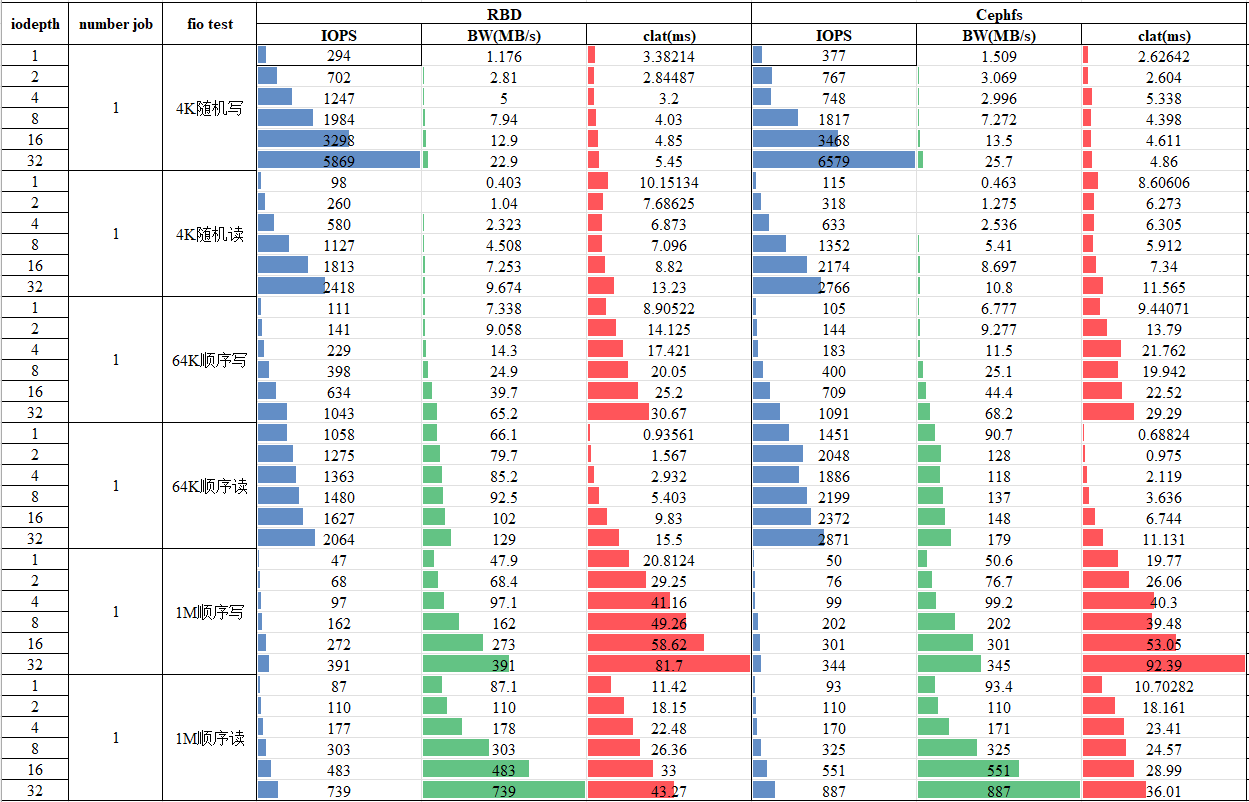
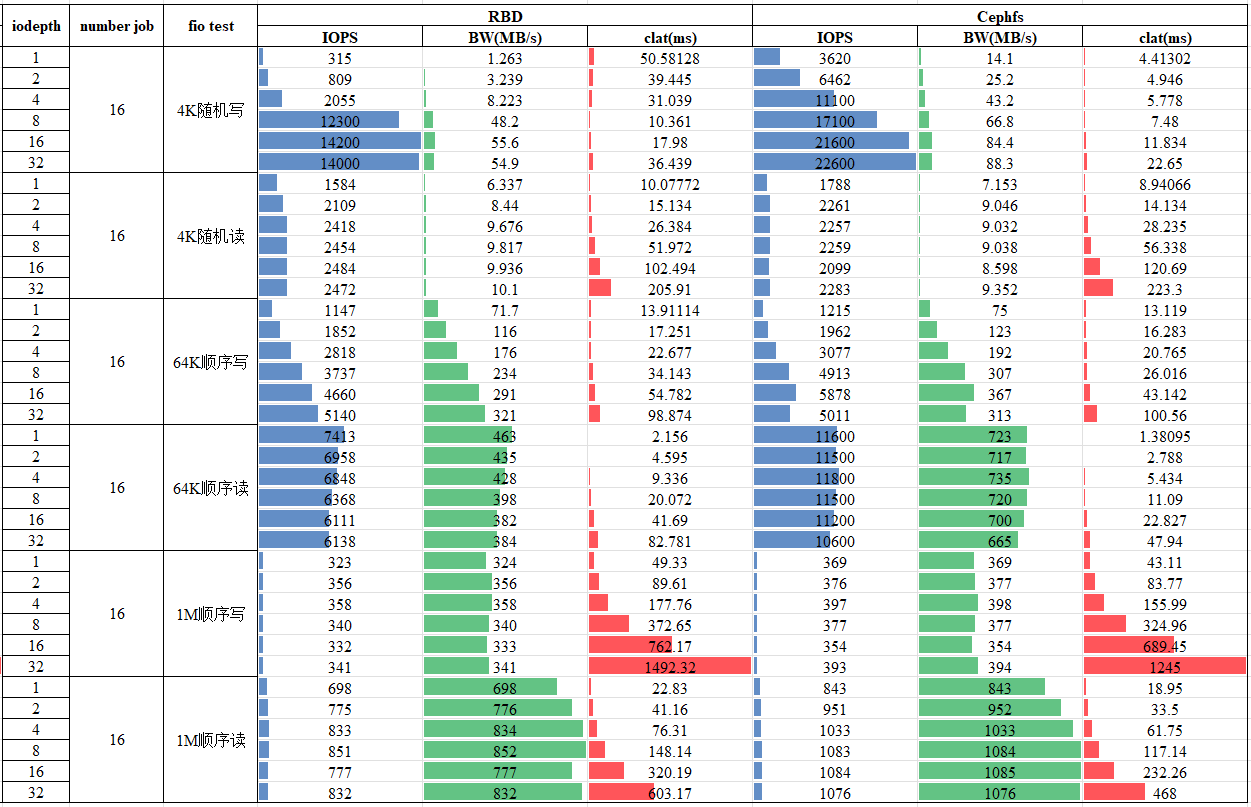
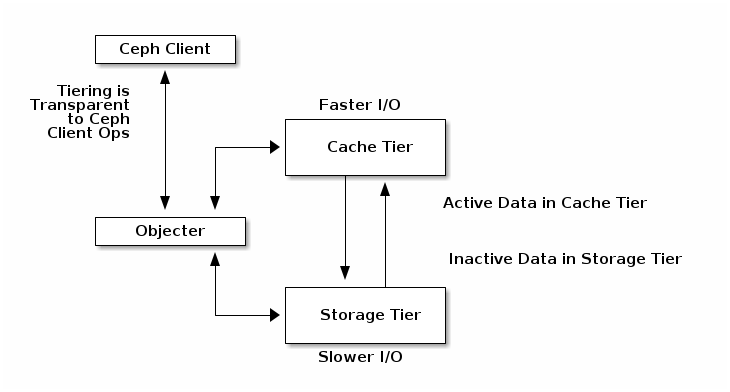



 ,而且7.x版本以后能明显感觉bug变少很多
,而且7.x版本以后能明显感觉bug变少很多
