新一代酷睿Ultra处理器Lunar Lake正式亮相
6月4日,在中国台北举行的COMPUTEX 2024展前发布会上,英特尔正式公布了新一代的AI PC处理器,也就是第二代酷睿Ultra中的移动版,代号为Lunar Lake的超低功耗处理器。

要知道,酷睿Ultra(Meteor Lake)是去年12月正式发布的,距今不过半年时间,彼时,酷睿Ultra以开创性的分离式模块架构,成为英特尔客户端SoC历史上40年来的重大变革。我们以为这种架构至少会延续一段时间,最起码不应该变得这么快,但从公布的Lunar Lake架构细节来看,信息量巨大,英特尔堪称在革自己的命,比如自2002年首次推出的超线程技术不再使用,比如首次将内存集成到封装内,比如Metor Lake的低功耗能效核心LP E只存活了一代…具体细节请看我们接下来的详细解析。

首先说明一点,Lunar Lake是针对轻薄笔记本、掌机类产品设计的,侧重于低功耗、高效能以及增强的AI能力,设计功耗(TDP)仅有17瓦。根据英特尔的路线图,后续的高性能移动版以及桌面版尚在开发中,Arrow Lake、Panther Lake还需要等待一段时间。
全新性能核心砍掉超线程 E核当做P核用
Lunar Lake延续了Meteor Lake的分离式模块架构,采用3D Foveros 封装技术,但唯一的不同是:处处不同。Lunar Lake是一个全方位创新的新一代平台,无论是计算部分、还是控制部分、以及AI部分都发生了巨大的变化。简单来说:Lunar?Lake的整体功耗相比上代下降了40%;核芯显卡的游戏和图形性能提高1.5倍;全新的NPU性能达前代4倍,平台AI算力高达120TOPS。?

先来看看整个芯片架构中的Compute Tile,也就是计算模块。首先,制造工艺升级为Intel 20A(台积电N3B制程),这也是英特尔“四年五制程节点”计划中的预定推进时间。

计算模块仍然采用混合架构设计,包含8个核心,4个性能核(P核)和4个能效核(E核),不再设有LP E,也就是低功耗能效核心,并且Lunar Lake只会提供这个规格的核心组合。

全新的性能核代号Lion Cove,首要的一个变化就是取消了超线程,也就是说英特尔自2002年发布超线程技术以来,首次在主流处理器平台上去掉了这个设置,原因也很简单,通过架构优化,在取消超线程的设置下,性能功耗比反而提升了,而且还提升了性能晶片尺寸比。当然,超线程就没有存在的必要了。

这也符合Lunar Lake的设计理念:去除任何对产品没有贡献的晶体管,以达到最高能效。Lion Cove着重优化了每瓦性能,这是衡量能效比的重要指标。它有2.5MB的L2缓存以及12MB的共享L3缓存,主要用来帮助实现出色的单线程性能。同时,这种微架构的突破为后续几代的P核设计奠定了新的基础。新的设计让性能核心实现了高达14%的代际性能提升,同时实现了更低的功耗。

全新的能效核心(Skymont)则是另外一种设计理念,Intel希望让E核能够涵盖更多的日常算力要求,日常应用、非极端重载的情况下,甚至不希望P核运行,从而降低能耗。所以Lunar Lake的E核是按照与Raptor Lake的P核性能相当的目标去设计的,同时还要保持E核级别的能效水平。

从12代酷睿之后的几代芯片中,E核已经被证明是比超线程更高效的一种多线程加速手段,也就是说如果要追求多线程性能,与其赋能超线程,不如去提高E核的能效。
在Lunar Lake上,这4个能效核有4MB的L2共享缓存,与Meteor Lake的LP E核心相比,能提供2倍的单线程性能和4倍的多线程性能,而且它增加了AI向量计算的吞吐量,使得其能够用于处理复杂的AI计算任务。
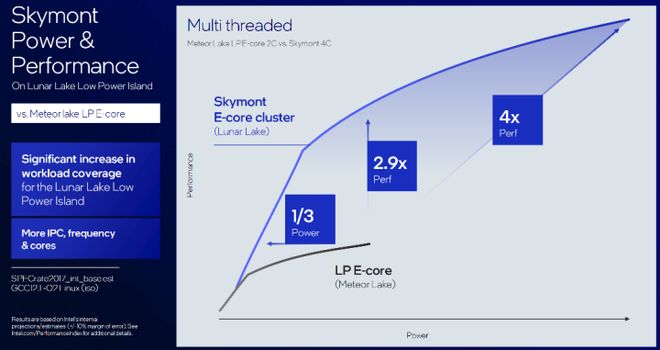
Skymont提高了核内并行处理能力,并在此基础上优化了能耗。和Raptor Lake的P核相比,IPC性能提高了2%,如果与Meteor Lake的LP E核相比,整数性能提升38%,浮点性能提升68%,非常可观。

功耗方面,和Meteor Lake的LP E核相比,Skymont仅用1/3的功耗就取得了一样的性能。因为Raptor Lake功耗涵盖的范围更广,可以跑在非常高的功耗区间,所以其绝对性能还是会超过Skymont,但Lunar Lake是面向移动端的产品,所以功耗范围是低于Raptor Lake的。因此在日常工作负载时,Skymont的性能表现相当领先,同样的性能下功耗只有Raptor Lake P核的60%,同功耗下,性能又比Raptor Lake的P核高出20%。

并且,Skymont核心的微架构是灵活的,Lunar Lake上只是4核心的配置,但在不久的将来,其它产品线,如桌面级处理器都会采用Skymont微架构。所以Skymont微架构的设计初衷不仅是低核心数,它也是非常适合于多核心的部署,这个架构是有延展性的。

通过以上的分析,我们不难发现Lunar Lake的性能核和能效核的设计形成了巧妙的互补,因为二者的完美协作,在广泛的任务当中能够既能体现它的性能优势,又能节省更多的功耗,帮助笔记本获得更长的续航时间。在较低功耗的区间,E核的性能实际上更强,但P核的功率上限更好,性能宽度拉得更极致。因此尽管P核取消了超线程,整个处理器的线程数量减少了,但Lunar Lake仍然能够取得多核性能的提升。

在性能核与能效核的调度方面,英特尔Lunar?Lake中的硬件线程调度器(Intel Thread Director)也有改进与优化,带来了动态调度策略、增强算法、更精细的控制,EEM也有更大的定制范围。硬件线程调度器会充分考虑能效,如工作负载合适将优先分配给单能效核,多线程时进行能效核扩展,再根据需求引导至性能核。同时配合操作系统隔离区、加强电源管理等设计,也可以提高能效。
率先采用Xe2架构GPU图形性能与AI双提升
接下来,我们来看看Lunar Lake的GPU部分,自Meteor上首次使用锐炫独显同源的Xe-LPG架构后,核芯显卡的性能有了明显的提升,这次Lunar Lake更加勇猛,甚至先于锐炫独显就用上了新一代的Xe2 GPU微架构。

代号为Battlemage的全新GPU设计结合了两项创新技术:Xe2 GPU核心用于图形处理、Xe矩阵扩展(XMX)阵列用于人工智能。

Xe2 GPU提供了8个Xe核心,同时还有8个光线追踪单元,和上一代相比,游戏和图形性能提高了1.5倍。全新的XMX矩阵扩展单元作为第2个AI加速器,可以提供高达67 TOPS的性能,为AI内容创作提供出色的吞吐量,能够为人工智能应用在集显上运行提供更好的性能。
总结来说,全新的Xe集显加上软件优化,与上一代相比图形性能提升超过50%,同时在人工智能的计算方面,有着3.5倍的提高。

除此之外,Lunar Lake也提供了非常好的视觉体验,全新设计了显示和媒体部分。媒体引擎增加了H.266,也就是VCC(多功能视频编码),VVC的优势在于降低比特率并保持同等画质,从而减少文件大小和传输压力,可自适应分辨率码率,更加灵活,还支持屏幕内容编码流(SCC)、360度全景码流。

显示部分,全新显示引擎可支持HDMI?2.1、DP?2.1、eDP?1.5,支持三路显示,低功耗的eDP可以确保能效核高质量的显示性能。Lunar Lake还提升了IPU影音处理单元的能力,主要提供了增强型的时域噪声抑制,以及多帧静态处理和改进的双重曝光校错HDR。
史上最强的AI算力 NPU性能提高3倍
既然是第二代AI PC,那么NPU自然是另一个重点。Lunar Lake上的NPU被命名为NPU 4.0,对,不是2.0而是4.0,因为事实上2018年的神经网络单元就是NPU的1.0版本。


全新的NPU 4与上一代的Meteor Lake相比,性能大幅提高3倍之多,算力达到48TOPS。英特尔表示Lunar Lake的NPU 4是“面向AI PC的最大的集成和专用AI加速器”。

NPU 4拥有12个用作向量计算的增强SHAVE?DSP,6个带有缓存的神经计算引擎,支持原生激活功能和数据转换以及大语言模型的嵌入标记化。新的NPU架构级效率提升,使得英特尔大规模人工智能战略向前又跨出了一大步。

当然,AI计算不能只靠NPU,Lunar Lake的AI性能仍然聚合了GPU、CPU与NPU的多元算力,把所有的XPU加在一起,一共可以提供高达120 TOPS的算力。通过三种XPU不同的性能特点,Lunar Lake能够使得所有的AI应用、用例得到完美的支持。这意味着更多参数的大模型可以在本地运行,更重负载的AI应用也能有更大的发挥空间。Lunar Lake将成为AI PC更强大的基石。
首次使用封装级内存 先进的平台控制模块
Lunar Lake还有另外一个极其重要的特性——封装级内存。通过使用新的MoP(Memory on Package)封装技术将内存芯片首次集成到SoC中,2颗内存容量最高32GB,支持LPDDR5x,每个芯片最高8.5GT/s(8500MHz),支持4个16bit通道。

由于内存就在SoC内部,因此缩短了内存走线,可以将Memory的物理功耗降低高达40%,这将带来更好的功耗表现,同时对于AI和图形性能的提升也有帮助。MOP还可以减少内存占用面积,从而使得PCB的层数能够降低,降低电路板设计的复杂性。
不过但要注意的是,使用MoP后,就不再支持外接内存,也就是笔记本的内存就是固定容量,不能再扩展了。

特别的是,Lunar Lake上首次引入了内存侧的缓存区(Memory side cache),用来提升系统效率和系统性能。它有8MB的物理缓存,能够把一些经常使用的数据缓存在这里,以减少对DRAM的访问,降低功耗,提高反应速度。同时,还可以缓存一些IO引擎,缓存区是高度可配置的,允许在引擎之间动态分配,适用于不同的应用。

Lunar Lake的平台控制模块(Platform Controller tile)也是一大亮点,集成了PCIe 5.0/4.0控制器、雷电4控制器、USB控制器、Wi-Fi与蓝牙控制器、安全引擎等,重点在连接性方面进行了提升。Lunar?Lake提供最多4条PCIe 5.0、4条PCIe?4.0总线通道,支持Wi-Fi 7(5G Gig),支持蓝牙5.4,支持雷电4及雷电共享技术。计算模块与平台控制模块通过可扩展第二代交叉总线以及D2D界面互联,另外Lunar?Lake还集成4个电源控制器,可实现增强遥测,可动态调节电压。Lunar Lake的电源管理架构也有了变化,独立的PMIC与全新的能效核心、增强的英特尔硬件线程调度器、内存侧缓存等一起,优化了能效,实现了整个SoC的既定设计目标。
变革之后是更大的变革 一切皆可再超越
去年发布的英特尔Meteor Lake平台,无论是技术层面,还是AI层面,都足以在英特尔的历史中成为浓墨重彩的一页,只是没想到,仅仅半年之后,英特尔就开始革自己的命,创新之上在创新,全新的Lunar Lake变化之大令我们感到惊讶。

也许正如英特尔公司创始人戈登·摩尔先生在2015年说的那句话一样,“WHATEVER HAS BEEN DONE, CAN BE OUTDONE”,超越永无止境,AI时代,一切才刚刚开始。

据悉,Lunar Lake目前已经进入晶圆和芯片量产阶段,将在第三季度正式发布。Lunar Lake将为来自20家OEM的80多款AI PC提供动力。英特尔预计在今年交付超过4000万片英特尔酷睿Ultra处理器。

当下,对于英特尔来说,还有另外一个最重要的事情就是持续加强与操作系统、ISV厂商、大模型厂商以及开发者们的合作,继续推动AI PC的生态建设,确保大模型以及软件能够在英特尔的GPU和NPU上有更深层的优化,以带给用户更好的体验。毕竟AI PC这个赛道上,AMD、高通都也在发力,千帆竞发,谁能勇立潮头?我们拭目以待!
 310112100042806
310112100042806


 发表于 2024-6-7 12:43
发表于 2024-6-7 12:43
 北京
北京  卖缓存吃相都这么难看了,还要卖内存,把客户都推给AMD吗?
卖缓存吃相都这么难看了,还要卖内存,把客户都推给AMD吗?