|
|
说下它们的配置:
CPU: Intel (R) Xeon (R) Gold 6454S 1T DRAM (2 NUMA nodes)
GPU: 4090D 24G VRAM
Memory: standard DDR5-4800 server DRAM (1 TB)
性能提升:
[NEW!!!] Local 671B DeepSeek-Coder-V3/R1: Running its Q4_K_M version using only 14GB VRAM and 382GB DRAM.
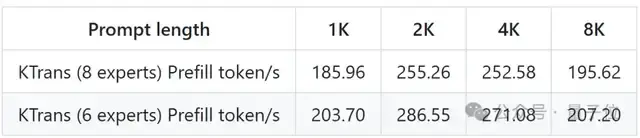
Prefill Speed (tokens/s):
KTransfermor: 54.21 (32 cores) → 74.362 (dual-socket, 2×32 cores) → 255.26 (optimized AMX-based MoE kernel, V0.3 only) → 286.55 (selectively using 6 experts, V0.3 only)
Compared to 10.31 tokens/s in llama.cpp with 2×32 cores, achieving up to 27.79× speedup.
Decode Speed (tokens/s):
KTransfermor: 8.73 (32 cores) → 11.26 (dual-socket, 2×32 cores) → 13.69 (selectively using 6 experts, V0.3 only)
Compared to 4.51 tokens/s in llama.cpp with 2×32 cores, achieving up to 3.03× speedup. |
|
 310112100042806
310112100042806


 发表于 2025-2-12 15:21
发表于 2025-2-12 15:21